Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
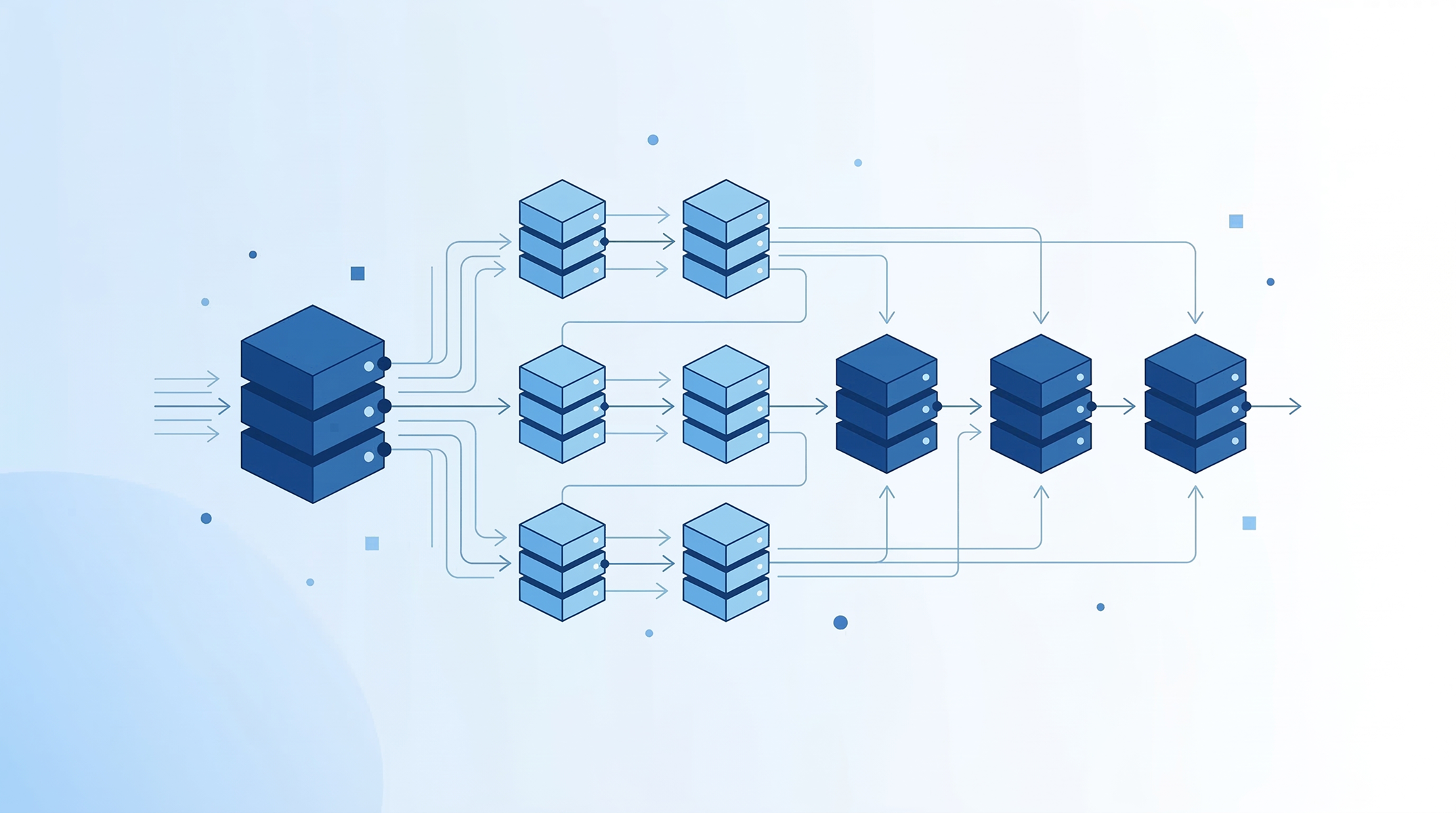
Bu yazı, OpenAI’ın ChatGPT gibi yüz milyonlarca kullanıcıya hizmet veren bir sistemi PostgreSQL kullanarak nasıl ölçeklendirdiğini anlatır. Yazıda read replica kullanımı, sorgu optimizasyonu, caching, connection pooling ve sharding gibi tekniklerle büyük ölçekli bir veritabanı mimarisinin nasıl verimli şekilde çalıştırılabildiği sade bir şekilde açıklanmaktadır.
Büyük ölçekli sistemler konuşulurken genellikle çok karmaşık mimariler hayal edilir: yüzlerce servis, dağıtık veri tabanları, karmaşık sharding stratejileri… Ancak gerçek dünyada işler çoğu zaman daha sade başlar.
OpenAI’ın paylaştığı bir teknik yazı ve bu yazıyı anlatan video, ChatGPT’nin yüz milyonlarca kullanıcıya ulaşmasına rağmen veri tabanı tarafında oldukça basit bir mimariyle çalıştığını gösteriyor.
Temel yapı şu:
İlk bakışta şaşırtıcı gelebilir. Ama aslında bu yaklaşım, modern sistem tasarımında çok önemli bir prensibi hatırlatıyor:
Önce basit başla, sorunlar ortaya çıktıkça ölçeklendir.
Bu yazıda, OpenAI’ın PostgreSQL’i bu ölçekte nasıl kullandığını ve hangi optimizasyonları yaptığını sade bir şekilde anlatacağım.
Hiç kimse ilk gününden sharding yapan dağıtık veri tabanı mimarisi ile başlamaz.
Genellikle süreç şu şekilde ilerler:
OpenAI da aynı yolu izlemiş.
Önce:
Çünkü ChatGPT gibi bir sistemde çoğu işlem okuma ağırlıklıdır.
Read replica, veritabanının sadece okuma yapan kopyalarıdır.
Yapı şu şekilde çalışır:
Primary DB
|
| replication
|
---------------------------------
| | | | |
Replica Replica Replica Replica ...
Bu sayede:
OpenAI bu yapıda 50 read replica kullanıyor.
Bu sayı kulağa çok gibi gelebilir ama milyonlarca kullanıcı için oldukça normal.
Okuma işlemleri kolay ölçeklenir.
Yeni read replica eklemek genellikle yeterlidir.
Ancak write (yazma) işlemleri çok daha karmaşıktır.
PostgreSQL’de bunun sebeplerinden biri MVCC (Multi-Version Concurrency Control) mekanizmasıdır.
MVCC şu şekilde çalışır:
Bir satır güncellendiğinde:
Bu durum iki probleme yol açar:
Her güncelleme yeni veri üretir.
Okuma sırasında sistem doğru versiyonu bulmak için birden fazla versiyonu kontrol eder.
Büyük ölçekte bu durum performans sorunlarına yol açabilir.
OpenAI’ın yaptığı önemli optimizasyonlardan biri:
Lazy writes
Yani:
Gerçek zamanlı yapılması gerekmeyen yazma işlemleri toplu olarak yapılır.
Bu yaklaşımın faydaları:
Bu aslında performans dünyasında çok önemli bir kuraldır:
Gerçek zamanlı olmak zorunda olmayan hiçbir işlem gerçek zamanlı yapılmamalıdır.
Veritabanı performansını en çok etkileyen şeylerden biri karmaşık join sorgularıdır.
OpenAI’ın blogunda verilen örneklerden biri oldukça dikkat çekici:
Bir sorgu 12 tabloyu join ediyordu.
Bu tür sorgular:
Bunun yerine yapılan şey:
Bu sayede:
Modern backend projelerinde ORM kullanmak çok yaygındır.
Ama ORM tarafından üretilen SQL her zaman en verimli SQL değildir.
Bu nedenle yapılan şey:
Özellikle şu problem çok yaygındır:
Bu problem yüzünden tek bir API çağrısı:
Büyük sistemlerde bu fark dramatiktir.
PostgreSQL’de her yeni bağlantı yeni bir process oluşturur.
Bu pahalı bir işlemdir.
Bu yüzden çoğu sistem PostgreSQL’in önüne bir connection pooler koyar.
En yaygın araçlardan biri:
PgBouncer
PgBouncer şu işi yapar:
Bu sayede:
ChatGPT gibi sistemler yoğun şekilde cache kullanır.
Ama cache’in bir problemi vardır:
Cache miss
Cache miss olduğunda:
Bunu önlemek için kullanılan teknik:
Mantık şu:
Cache boşsa:
Bu sayede veritabanı ani yükten korunur.
Bu yöntem CDN’lerde de kullanılır.
OpenAI mimarisinde:
Primary çökerse ne olur?
Bunun için hot standby kullanılır.
Hot standby:
Bu sayede sistem tamamen çökmez.
OpenAI şu anda bazı iş yüklerini sharded veritabanlarına taşımaya başlamış.
Örneğin:
Özellikle yeni özellikler için:
Ama önemli bir detay var:
Eski sistem tamamen terk edilmemiş.
Yani sistem evrimsel olarak büyüyor.
50 read replica bile bir noktada limit olabilir.
Bunun çözümü olarak düşündükleri yöntem:
Cascading replication
Yapı şu şekilde:
Primary
|
Intermediate Replica
|
--------------------------------
| | | | |
Replica Replica Replica Replica
Yani:
Primary → ara replica → read replica
Bu yöntem sayesinde:
OpenAI’ın PostgreSQL mimarisine baktığımızda aslında çok önemli bir ders görüyoruz:
Büyük ölçekli sistemler her zaman karmaşık olmak zorunda değildir.
Doğru optimizasyonlarla:
gibi tekniklerle tek bir veritabanı bile yüz milyonlarca kullanıcıya hizmet verebilir.
Asıl önemli olan şey:
Çoğu zaman “yeni teknoloji” değil, mevcut sistemi doğru kullanmak daha büyük fark yaratır.
Bu yazı “How OpenAI Handles 800 Million ChatGPT Users on a Single PostgreSQL Primary” videosundan ilham alınarak yazılmıştır.



