Veri Modelleme Temelleri
Veri modelinin amacı ve önemi
Veri modeli, bir organizasyonun verilerinin yapısını, ilişkilerini ve kısıtlamalarını tanımlayan bir çerçevedir. Temel amaçları şunlardır:
- Veri Yapısını Anlaşılır Kılmak: Verilerin nasıl organize edildiğini ve birbirleriyle nasıl ilişkili olduğunu görselleştirir.
- Veri Tutarlılığını Sağlamak: Farklı sistemler ve ekipler arasında standart bir veri tanımı sunar.
- Veri Yönetimini Kolaylaştırmak: Veri tabanı tasarımı, veri entegrasyonu ve analitik süreçler için temel oluşturur.
- İş Gereksinimlerini Desteklemek: İş süreçlerini optimize etmek için verilerin doğru ve etkili bir şekilde kullanılmasını sağlar.
İş Süreçlerine Katkıları
Veri modelleri, iş süreçlerini aşağıdaki yollarla destekler:
- Veri Erişimini Hızlandırır: İyi tasarlanmış bir veri modeli, veri sorgularını optimize ederek analitik ve raporlama süreçlerini hızlandırır. Örneğin, bir perakende şirketi, stok verilerini hızlıca analiz ederek tedarik zinciri kararlarını iyileştirebilir.
- Veri Kalitesini Artırır: Standartlaştırılmış veri tanımları, veri giriş hatalarını azaltır ve tutarlılık sağlar. Örneğin, bir hastanede hasta kayıtlarının doğru modellenmesi, yanlış tedavilerin önüne geçer.
- Sistem Entegrasyonunu Kolaylaştırır: Farklı sistemler arasında veri akışını düzenler. Örneğin, bir CRM ve ERP sistemi arasında veri modeli, müşteri verilerinin sorunsuz paylaşımını sağlar.
- Stratejik Karar Alma: Veri modelleri, iş zekası araçlarının doğru verilere erişmesini sağlayarak stratejik kararları destekler. Örneğin, bir banka, kredi risk analizini veri modeli üzerinden gerçekleştirir.
Gerçek Dünya Örneği: Amazon, ürün kataloglarını, müşteri verilerini ve sipariş geçmişini yönetmek için karmaşık veri modelleri kullanır. Bu modeller, öneri sistemlerini güçlendirir ve lojistik süreçlerini optimize ederek müşteri memnuniyetini artırır.
Veri Modellemede En Sık Yapılan Hatalar
İş Gereksinimlerini Göz Ardı Etme:
- Hata: Model, iş ihtiyaçlarını değil, yalnızca teknik gereksinimleri karşılar.
- Örnek: Bir e-ticaret platformu, müşteri segmentasyonunu desteklemeyen bir veri modeli kullanırsa, pazarlama kampanyaları etkisiz kalır.
- Çözüm: İş paydaşlarıyla yakın iş birliği yaparak gereksinimleri netleştirmek.
Aşırı Karmaşık veya Yetersiz Model Tasarımı:
- Hata: Gereksiz detaylarla karmaşıklaşan veya çok basit modeller, performansı düşürür.
- Örnek: Bir sigorta şirketi, tüm müşteri verilerini tek bir tabloda toplamaya çalışırsa, sorgular yavaşlar ve bakım zorlaşır.
- Çözüm: Normalizasyon ve denormalizasyon dengesini iyi kurmak.
Veri İlişkilerini Yanlış Tanımlama:
- Hata: Yanlış anahtar ilişkileri veya eksik kısıtlamalar, veri tutarsızlığına yol açar.
- Örnek: Bir okul yönetim sisteminde öğrenci ve ders ilişkileri yanlış tanımlanırsa, bir öğrenci yanlış sınıfa atanabilir.
- Çözüm: İlişkisel veri tabanı ilkelerine (ör. foreign key) bağlı kalmak.
Gelecek İhtiyaçlarını Düşünmeme:
- Hata: Model, mevcut ihtiyaçlara odaklanır ve ölçeklenebilirlik göz ardı edilir.
- Örnek: Bir startup, başlangıçta basit bir veri modeli kullanır, ancak büyüdükçe yeni veri türlerini destekleyemez.
- Çözüm: Esnek ve modüler bir tasarım benimsemek.
Dökümantasyon Eksikliği:
- Hata: Modelin amacı ve yapısı belgelenmez, bu da bakım ve geliştirme süreçlerini zorlaştırır.
- Örnek: Bir finans şirketinde veri modelinin dökümantasyonu eksikse, yeni bir geliştirici sistemi anlamakta zorlanır.
- Çözüm: Veri sözlüğü ve şema dökümantasyonu oluşturmak.
Gerçek Dünya Örnekleri
- Hata Örneği (Uber): Uber’in erken dönemlerinde, veri modeli yerel pazar ihtiyaçlarını tam desteklemiyordu. Örneğin, bazı şehirlerdeki ödeme sistemleri için ek alanlar gerekiyordu, ancak model bu esnekliği sağlamıyordu. Bu, yeni özelliklerin entegrasyonunu yavaşlattı. Uber, modeli modüler hale getirerek bu sorunu çözdü.
- Başarı Örneği (Netflix): Netflix’in veri modeli, kullanıcı davranışlarını (izleme geçmişi, beğeniler) ve içerik metadatalarını etkili bir şekilde ilişkilendirir. Bu, kişiselleştirilmiş öneriler sunarak kullanıcı deneyimini güçlendirir ve iş süreçlerini optimize eder.
Kavramsal, mantıksal ve fiziksel veri modelleri arasındaki farklar
1. Kavramsal Veri Modeli
Tanım: Kavramsal veri modeli, verilerin iş açısından yüksek seviyeli bir temsilini sağlar. İş süreçlerini ve temel veri varlıklarını (entities) tanımlar, ancak teknik detaylara girmez.
Özellikler:
- İş odaklıdır ve teknik detaylardan bağımsızdır.
- Genellikle varlık-ilişki diyagramları (ERD) kullanılarak temsil edilir.
- Varlıklar (ör. Müşteri, Sipariş) ve aralarındaki ilişkiler (ör. Müşteri Sipariş Verir) tanımlanır.
- Veritabanı teknolojisinden bağımsızdır.
Örnek: Bir e-ticaret sistemi için kavramsal model, “Müşteri”, “Ürün” ve “Sipariş” gibi varlıkları ve bunların ilişkilerini (ör. Müşteri Sipariş Verir) içerir.
Dikkat Edilmesi Gerekenler:
- İş Gereksinimlerinin Netliği: İş paydaşlarıyla yakın iş birliği yapılarak gereksinimler doğru anlaşılmalıdır.
- Basitlik: Model, gereksiz detaylardan arındırılmış ve anlaşılır olmalıdır.
- Tam Kapsayıcılık: Tüm temel iş varlıkları ve ilişkileri tanımlanmalıdır.
- Esneklik: Gelecekteki iş ihtiyaçlarını destekleyecek şekilde tasarlanmalıdır.
2. Mantıksal Veri Modeli
Tanım: Mantıksal veri modeli, kavramsal modelin daha ayrıntılı bir versiyonudur. Verilerin yapısını, ilişkilerini ve kısıtlamalarını tanımlar, ancak hala fiziksel depolama detaylarından bağımsızdır.
Özellikler:
- Varlıkların öznitelikleri (attributes) (ör. Müşteri: Ad, Soyad, E-posta) tanımlanır.
- Birincil ve yabancı anahtarlar (primary/foreign keys) gibi ilişkisel yapılar belirtilir.
- Normalizasyon kuralları uygulanır (ör. 1NF, 2NF, 3NF).
- Veritabanı yönetim sistemi (DBMS) bağımsızdır.
Örnek: E-ticaret örneğinde, mantıksal model, Müşteri tablosunda “MüşteriID (PK)”, “Ad”, “Soyad” gibi öznitelikleri ve Sipariş tablosuyla ilişkisini (ör. MüşteriID foreign key) içerir.
Dikkat Edilmesi Gerekenler:
- Normalizasyon: Verinin tekrarını önlemek ve tutarlılığı sağlamak için normalizasyon doğru uygulanmalıdır.
- Veri Bütünlüğü: Anahtarlar ve kısıtlamalar (ör. NOT NULL, UNIQUE) doğru tanımlanmalıdır.
- İlişkilerin Doğruluğu: Varlıklar arasındaki ilişkiler (1:1, 1:N, N:N) doğru modellenmelidir.
- Performans Dengesi: Aşırı normalizasyon, performans sorunlarına yol açabilir; bu nedenle iş ihtiyaçlarına uygun bir denge kurulmalıdır.
3. Fiziksel Veri Modeli
Tanım: Fiziksel veri modeli, mantıksal modelin belirli bir veritabanı teknolojisine (ör. MySQL, Oracle) uyarlanmış halidir. Verilerin nasıl depolanacağını, indeksleneceğini ve optimize edileceğini tanımlar.
Özellikler:
- Tablo yapıları, sütun veri türleri (ör. VARCHAR, INT) ve indeksler tanımlanır.
- Depolama detayları (ör. partition, tablespace) belirtilir.
- Performans optimizasyonları (ör. indeksler, denormalizasyon) uygulanır.
- Veritabanı teknolojisine özgü özellikler kullanılır.
Örnek: E-ticaret örneğinde, fiziksel model, Müşteri tablosunda “MüşteriID INT PRIMARY KEY”, “Ad VARCHAR(50)” gibi sütunlar ve performans için indeksler içerir.
Dikkat Edilmesi Gerekenler:
- Performans Optimizasyonu: Sık kullanılan sorgular için indeksler ve uygun veri türleri seçilmelidir.
- Depolama Kısıtlamaları: Veritabanı sisteminin depolama kapasitesi ve sınırlamaları dikkate alınmalıdır.
- Güvenlik: Veri erişim kontrolleri ve şifreleme gibi güvenlik önlemleri tanımlanmalıdır.
- Bakım Kolaylığı: Model, gelecekteki güncellemeler ve bakım için esnek olmalıdır.
Modeller Arasındaki Dönüşüm Süreçleri
Veri modelleme, genellikle kavramsal modelden başlayarak mantıksal ve fiziksel modellere doğru ilerleyen bir süreçtir. Dönüşüm süreçleri şöyledir:
Kavramsaldan Mantıksala Dönüşüm:
- Adımlar:
- Kavramsal modeldeki varlıklar, mantıksal modelde tablolara dönüştürülür.
- Varlıkların öznitelikleri tanımlanır (ör. Müşteri için Ad, Soyad).
- İlişkiler, birincil ve yabancı anahtarlarla ifade edilir.
- Normalizasyon uygulanarak veri tekrarı önlenir.
- Kritik Noktalar:
- İş gereksinimlerinin tam olarak yansıtıldığından emin olun.
- İlişkilerin doğru tanımlandığını kontrol edin (ör. 1:N ilişkisi için yabancı anahtar).
- Gereksiz özniteliklerden kaçının.
- Örnek: Kavramsal modelde “Müşteri Sipariş Verir” ilişkisi, mantıksal modelde Sipariş tablosunda “MüşteriID” yabancı anahtarı olarak tanımlanır.
Mantıksaldan Fiziksele Dönüşüm:
- Adımlar:
- Mantıksal modeldeki tablolar, belirli bir DBMS’ye uygun fiziksel tablolara dönüştürülür.
- Öznitelikler için veri türleri (ör. VARCHAR, INT) ve kısıtlamalar belirlenir.
- Performans için indeksler, partition’lar veya denormalizasyon uygulanır.
- Depolama yapıları (ör. tablespace) ve güvenlik ayarları tanımlanır.
- Kritik Noktalar:
- DBMS’nin özelliklerine ve sınırlamalarına uygun tasarım yapılmalıdır.
- Performans testleri yapılarak sorgu hızı optimize edilmelidir.
- Gelecekteki ölçeklendirme ihtiyaçları göz önünde bulundurulmalıdır.
- Örnek: Mantıksal modeldeki “Ad” özniteliği, fiziksel modelde “VARCHAR(50) NOT NULL” olarak tanımlanır ve sık sorgulanıyorsa indeks eklenir.
Genel Kritik Noktalar
- Paydaş İş Birliği: Her aşamada iş paydaşları, veri mimarları ve geliştiriciler arasında iletişim sağlanmalıdır.
- Dökümantasyon: Her modelin amacı, yapısı ve kararları belgelenmelidir.
- Esneklik ve Ölçeklenebilirlik: Modeller, gelecekteki iş ihtiyaçlarını ve veri hacmi artışını desteklemelidir.
- Test ve Doğrulama: Her aşamada modelin doğruluğu ve performansı test edilmelidir.
Gerçek Dünya Örneği
Amazon’un Veri Modelleme Süreci:
- Kavramsal Model: Amazon, müşteri, ürün ve sipariş gibi temel varlıkları tanımlayarak iş süreçlerini (ör. satın alma, öneri sistemi) modeller.
- Mantıksal Model: Bu varlıklar, öznitelikler (ör. Ürün: Fiyat, Kategori) ve ilişkilerle (ör. Müşteri-Ürün ilişkisi) detaylandırılır. Normalizasyon uygulanır.
- Fiziksel Model: Amazon’un kullandığı DynamoDB gibi NoSQL veritabanına uygun tablo yapıları ve indeksler tanımlanır. Örneğin, ürün aramaları için ikincil indeksler eklenir.
Hata Örneği: Bir sağlık kuruluşu, kavramsal modelde hasta ve tedavi ilişkisini eksik tanımlarsa, mantıksal modelde yanlış anahtar ilişkileri oluşabilir. Bu, fiziksel modelde veri tutarsızlığına yol açar (ör. bir hastanın yanlış tedaviye atanması).
Veri modelleme notasyonları (ER, UML, IDEF1X)
1. ER (Entity-Relationship) Notasyonu
Tanım: ER notasyonu, varlık-ilişki diyagramları (ERD) ile veri modellerini temsil eder. Varlıklar (entities), öznitelikler (attributes) ve ilişkiler (relationships) temel bileşenlerdir.
Avantajları:
- Basitlik ve Anlaşılırlık: ER diyagramları, hem teknik hem de iş paydaşları için kolayca anlaşılır.
- Veritabanı Tasarımına Odaklanma: İlişkisel veritabanı tasarımı için özel olarak geliştirilmiştir.
- Standartlaşma: Yaygın kullanımı sayesinde birçok veritabanı tasarım aracı tarafından desteklenir (ör. MySQL Workbench, ERwin).
- Esneklik: Hem kavramsal hem de mantıksal modelleme için kullanılabilir.
Dezavantajları:
- Sınırlı Kapsam: Nesne yönelimli sistemler veya karmaşık iş mantığı için yetersiz kalabilir.
- Standartlaşma Eksikliği: Farklı araçlar ve uygulayıcılar arasında notasyon varyasyonları olabilir (ör. Chen vs. Crow’s Foot).
- Karmaşık Sistemlerde Yetersizlik: Büyük ve karmaşık sistemlerde detaylı süreç modellemesi için ek notasyonlar gerekebilir.
Uygun Olduğu Projeler:
- İlişkisel Veritabanı Tasarımı: Küçük ve orta ölçekli veritabanı projelerinde (ör. bir e-ticaret platformunun müşteri, ürün ve sipariş verilerini modelleme).
- Basit İş Süreçleri: İş paydaşlarının teknik bilgiye ihtiyaç duymadan veri yapısını anlaması gereken projelerde.
- Örnek: Bir perakende şirketi, stok yönetimi için Müşteri, Ürün ve Sipariş varlıklarını modellemek için ER notasyonunu kullanabilir. Crow’s Foot notasyonu ile 1:N ilişkileri (ör. bir müşteri birden çok sipariş verebilir) kolayca gösterilir.
2. UML (Unified Modeling Language) Notasyonu
Tanım: UML, yazılım sistemlerini modellemek için standart bir dil sunar. Veri modellemesi için genellikle sınıf diyagramları (class diagrams) kullanılır, ancak diğer diyagram türleri (ör. use case, sequence) ile sistem tasarımı da desteklenir.
Avantajları:
- Kapsayıcılık: Veri modellemenin ötesinde, sistem davranışlarını ve süreçlerini (ör. use case, sequence diagrams) modelleyebilir.
- Nesne Yönelimli Tasarım: Sınıf diyagramları, nesne yönelimli programlama (OOP) ile uyumludur ve kalıtım, polimorfizm gibi kavramları destekler.
- Standartlaşma: OMG (Object Management Group) tarafından standartlaştırılmıştır, bu nedenle tutarlı bir kullanım sağlar.
- Geniş Araç Desteği: Enterprise Architect, Visual Paradigm gibi araçlarla yaygın desteklenir.
Dezavantajları:
- Karmaşıklık: UML’nin geniş kapsamı, öğrenme eğrisini artırabilir ve basit projelerde gereksiz yere karmaşık gelebilir.
- Veritabanı Odaklı Olmaması: İlişkisel veritabanı tasarımı için ER notasyonu kadar özel değildir; fiziksel modellemeye geçişte ek çaba gerekebilir.
- İş Paydaşları için Zorluk: Teknik olmayan paydaşlar için sınıf diyagramları anlaşılması zor olabilir.
Uygun Olduğu Projeler:
- Nesne Yönelimli Yazılım Geliştirme: Yazılım sistemlerinin hem veri hem de davranışlarını modellemek için (ör. bir bankacılık uygulamasında hesap yönetimi).
- Karmaşık Sistemler: Çoklu modüller ve süreçler içeren projelerde (ör. bir ERP sistemi).
- Örnek: Bir bankacılık uygulamasında, UML sınıf diyagramları ile “Hesap” ve “Müşteri” sınıfları, kalıtım (ör. Bireysel Hesap, Kurumsal Hesap) ve metodlar (ör. paraYatir()) modellenebilir. UML’nin sequence diyagramları, para transferi sürecini görselleştirebilir.
3. IDEF1X Notasyonu
Tanım: IDEF1X, veri modellemesi için özel olarak tasarlanmış bir notasyondur ve özellikle kurumsal veri yönetimi ve entegrasyon projelerinde kullanılır. Varlık-ilişki modellemesine dayanır, ancak daha katı kuralları vardır.
Avantajları:
- Detaylı ve Kesin Kurallar: IDEF1X, veri bütünlüğü ve ilişkisel tasarım için kesin standartlar sunar (ör. bağımlı/bağımsız varlıklar).
- Kurumsal Veri Yönetimi: Büyük ölçekli ve karmaşık veri entegrasyon projelerine uygun.
- Normalizasyon Desteği: Veritabanı normalizasyon kurallarını (1NF, 2NF, 3NF) destekler ve veri tutarlılığını sağlar.
- Resmi Dökümantasyon: Devlet ve savunma projelerinde sıkça kullanılan resmi bir standarttır.
Dezavantajları:
- Karmaşıklık: Katı kuralları ve terminolojisi, öğrenmeyi ve uygulamayı zorlaştırabilir.
- Sınırlı Kullanım Alanı: Nesne yönelimli sistemler veya süreç modellemesi için uygun değildir.
- Erişim Zorluğu: ER ve UML kadar yaygın araç desteği yoktur; özel araçlar gerekebilir.
- İş Paydaşları için Anlaşılmazlık: Teknik olmayan kullanıcılar için fazla karmaşık olabilir.
Uygun Olduğu Projeler:
- Kurumsal Veri Entegrasyonu: Farklı sistemler arasında veri tutarlılığı gerektiren projelerde (ör. bir hükümet veri tabanı).
- Büyük Ölçekli Veritabanları: Yüksek veri bütünlüğü gerektiren projelerde (ör. bir sigorta şirketinin müşteri ve poliçe verileri).
- Örnek: Bir sigorta şirketi, müşteri, poliçe ve talep verilerini entegre etmek için IDEF1X kullanabilir. IDEF1X’in bağımlı varlık tanımları, bir talebin mutlaka bir poliçeye bağlı olmasını garanti eder.
Karşılaştırmalı Analiz Tablosu
| Kriter | ER Notasyonu | UML Notasyonu | IDEF1X Notasyonu |
|---|---|---|---|
| Amaç | İlişkisel veritabanı tasarımı | Yazılım sistemi ve nesne yönelimli modelleme | Kurumsal veri modelleme ve entegrasyon |
| Kapsam | Varlık-ilişki odaklı | Veri, süreç ve davranış modelleme | Detaylı veri modelleme |
| Kolaylık | Basit ve anlaşılır | Orta derecede karmaşık | Karmaşık ve teknik |
| Standartlaşma | Kısmen standart (varyasyonlar var) | Yüksek (OMG standardı) | Yüksek (resmi standart) |
| Araç Desteği | Geniş (MySQL Workbench, ERwin) | Geniş (Enterprise Architect, Visio) | Sınırlı (özel araçlar) |
| İş Paydaşları için Uygunluk | Yüksek | Orta | Düşük |
| Normalizasyon Desteği | Orta | Düşük | Yüksek |
| Nesne Yönelimli Destek | Yok | Yüksek | Yok |
Hangi Notasyon Hangi Projede Uygun?
ER Notasyonu:
- Uygun Olduğu Durumlar:
- Küçük ve orta ölçekli ilişkisel veritabanı projeleri.
- İş paydaşlarının veri modelini anlaması gereken projeler.
- Hızlı prototipleme ve kavramsal modelleme.
- Örnek: Bir restoran zinciri, sipariş ve rezervasyon sistemini tasarlamak için ER notasyonunu kullanabilir. Müşteri, Sipariş ve Menü varlıkları arasındaki ilişkiler basitçe modellenir.
- Neden Uygun?: Basitliği ve ilişkisel veritabanı tasarımına odaklanması, hızlı geliştirme ve iş paydaşlarıyla iletişimi kolaylaştırır.
UML Notasyonu:
- Uygun Olduğu Durumlar:
- Nesne yönelimli yazılım geliştirme projeleri.
- Veri modellemenin yanı sıra süreç ve davranış modellemesi gereken projeler.
- Karmaşık sistemler ve modüler tasarımlar.
- Örnek: Bir sağlık uygulaması, hasta kayıtlarını (sınıf diyagramı), doktor randevu süreçlerini (sequence diyagramı) ve kullanıcı rollerini (use case diyagramı) modellemek için UML kullanabilir.
- Neden Uygun?: UML’nin geniş kapsamı, hem veri hem de sistem davranışlarını modellemeyi mümkün kılar ve nesne yönelimli sistemlerle uyumludur.
IDEF1X Notasyonu:
- Uygun Olduğu Durumlar:
- Büyük ölçekli kurumsal veri entegrasyon projeleri.
- Yüksek veri bütünlüğü ve normalizasyon gerektiren sistemler.
- Resmi standartların zorunlu olduğu projeler (ör. devlet, savunma).
- Örnek: Bir hükümet kurumu, vatandaş verilerini (nüfus, vergi, sosyal güvenlik) entegre etmek için IDEF1X kullanabilir. Bağımlı varlık tanımları, veri tutarlılığını sağlar.
- Neden Uygun?: IDEF1X’in katı kuralları, karmaşık ve kritik veri sistemlerinde tutarlılık ve doğruluk sağlar.
Gerçek Dünya Örnekleri
- ER Kullanımı (Amazon): Amazon’un erken dönemlerinde, ürün kataloğu ve müşteri verilerini modellemek için ER notasyonu kullanıldı. Basitliği sayesinde hızlı prototipleme yapıldı ve iş paydaşları veri yapısını kolayca anladı.
- UML Kullanımı (Netflix): Netflix, öneri sistemini ve kullanıcı arayüzünü tasarlamak için UML sınıf ve sequence diyagramlarını kullandı. Nesne yönelimli tasarımı, sistemin modülerliğini ve ölçeklenebilirliğini artırdı.
- IDEF1X Kullanımı (ABD Savunma Bakanlığı): ABD Savunma Bakanlığı, lojistik ve personel verilerini entegre etmek için IDEF1X’i tercih etti. Katı kuralları, farklı sistemler arasında veri tutarlılığını sağladı.
İlişkisel Veritabanı Konseptleri
Tablolar, satırlar ve sütunlar
1. Temel Bileşenler
a. Tablolar (Tables)
- Tanım: Verilerin organize edildiği temel yapıdır. Her tablo, belirli bir varlık türünü (ör. Müşteri, Sipariş) temsil eder.
- Özellikler: Tablolar, satır ve sütunlardan oluşur. Her tablo benzersiz bir isme sahiptir ve belirli bir şemaya göre tanımlanır.
- Örnek: Bir e-ticaret sisteminde
MusterilerveSiparislertabloları.
b. Satırlar (Rows)
- Tanım: Bir tabloda tek bir veri kaydını temsil eder. Her satır, tablonun temsil ettiği varlığın bir örneğidir.
- Özellikler: Satırlar, tablonun sütunlarına karşılık gelen değerler içerir. Bir tablodaki her satır benzersiz olmalıdır (genellikle birincil anahtar ile).
- Örnek:
Musterilertablosunda bir satır, belirli bir müşterinin bilgilerini (ör. ID, ad, e-posta) içerir.
c. Sütunlar (Columns)
- Tanım: Tablodaki her satırda saklanan veri türlerini tanımlar. Her sütun, belirli bir özniteliği (attribute) temsil eder.
- Özellikler: Sütunlar, veri tipi (ör. INT, VARCHAR) ve kısıtlamalar (ör. NOT NULL) ile tanımlanır.
- Örnek:
Musterilertablosunda sütunlar:MusteriID,Ad,Eposta.
2. Bileşenler Arasındaki İlişkiler
İlişkisel veritabanlarında tablolar, birincil anahtarlar (primary keys) ve yabancı anahtarlar (foreign keys) aracılığıyla birbirine bağlanır. Bu ilişkiler, veri bütünlüğünü sağlar ve veriler arasında anlamlı bağlantılar kurar.
a. Birincil Anahtar (Primary Key)
- Tanım: Bir tablodaki her satırı benzersiz şekilde tanımlayan bir sütun veya sütun kombinasyonudur.
- Özellikler: Tekrar eden veya NULL değerler içeremez.
- Örnek:
MusterilertablosundaMusteriIDbirincil anahtar olabilir.
b. Yabancı Anahtar (Foreign Key)
- Tanım: Bir tablodaki bir sütun, başka bir tablonun birincil anahtarına referans verir. Bu, tablolar arasında ilişki kurar.
- Özellikler: Yabancı anahtar, referans aldığı tablonun birincil anahtarında bulunan bir değere sahip olmalıdır.
- Örnek:
SiparislertablosundakiMusteriID,MusterilertablosununMusteriIDsütununa referans veren bir yabancı anahtardır.
c. İlişki Türleri
- 1:1 (Bire Bir): Bir tablodaki bir satır, diğer tablodaki yalnızca bir satırla ilişkilidir. Ör. Bir müşterinin tek bir pasaport kaydı.
- 1:N (Bire Çok): Bir tablodaki bir satır, diğer tablodaki birden çok satırla ilişkilidir. Ör. Bir müşteri birden çok sipariş verebilir.
- N:N (Çoka Çok): İki tablodaki satırlar birbirleriyle çoklu ilişkiler kurar. Bu, bir ara tablo (junction table) ile modellenir. Ör. Öğrenciler ve dersler arasındaki ilişki.
3. SQL Örnekleri
Bir e-ticaret veritabanı örneği üzerinden temel bileşenler ve ilişkiler SQL ile gösterilmiştir.
a. Tabloları Oluşturma
-- Musteriler tablosu
CREATE TABLE Musteriler (
MusteriID INT PRIMARY KEY,
Ad VARCHAR(50) NOT NULL,
Soyad VARCHAR(50) NOT NULL,
Eposta VARCHAR(100) UNIQUE
);
-- Siparisler tablosu
CREATE TABLE Siparisler (
SiparisID INT PRIMARY KEY,
MusteriID INT,
SiparisTarihi DATE NOT NULL,
ToplamTutar DECIMAL(10, 2),
FOREIGN KEY (MusteriID) REFERENCES Musteriler(MusteriID)
);- Açıklama:
MusterilertablosundaMusteriIDbirincil anahtar.SiparislertablosundaMusteriID,Musterilertablosuna yabancı anahtar olarak bağlanıyor (1:N ilişki).
b. Veri Ekleme
-- Musteriler tablosuna veri ekleme
INSERT INTO Musteriler (MusteriID, Ad, Soyad, Eposta)
VALUES (1, 'Ahmet', 'Yılmaz', 'ahmet@example.com'),
(2, 'Ayşe', 'Kaya', 'ayse@example.com');
-- Siparisler tablosuna veri ekleme
INSERT INTO Siparisler (SiparisID, MusteriID, SiparisTarihi, ToplamTutar)
VALUES (101, 1, '2025-05-01', 150.50),
(102, 1, '2025-05-03', 89.90),
(103, 2, '2025-05-04', 200.00);- Açıklama:
Siparislertablosuna eklenen her satır,Musterilertablosunda var olan birMusteriID’ye referans verir.
c. Veri Sorgulama (İlişkisel Sorgu)
-- Müşterilerin siparişleriyle birlikte listelenmesi (JOIN)
SELECT M.Ad, M.Soyad, S.SiparisID, S.SiparisTarihi, S.ToplamTutar
FROM Musteriler M
JOIN Siparisler S ON M.MusteriID = S.MusteriID;- Çıktı Örneği:
Ad Soyad SiparisID SiparisTarihi ToplamTutar
Ahmet Yılmaz 101 2025-05-01 150.50
Ahmet Yılmaz 102 2025-05-03 89.90
Ayşe Kaya 103 2025-05-04 200.00- Açıklama:
JOINkomutu,MusterilerveSiparislertablolarınıMusteriIDüzerinden birleştirir.
d. N:N İlişki Örneği
Öğrenciler ve dersler arasındaki çoka çok ilişkiyi modellemek için bir ara tablo kullanılır:
-- Ogrenciler tablosu
CREATE TABLE Ogrenciler (
OgrenciID INT PRIMARY KEY,
Ad VARCHAR(50) NOT NULL
);
-- Dersler tablosu
CREATE TABLE Dersler (
DersID INT PRIMARY KEY,
DersAdi VARCHAR(50) NOT NULL
);
-- Ara tablo (Ogrenci_Ders)
CREATE TABLE Ogrenci_Ders (
OgrenciID INT,
DersID INT,
PRIMARY KEY (OgrenciID, DersID),
FOREIGN KEY (OgrenciID) REFERENCES Ogrenciler(OgrenciID),
FOREIGN KEY (DersID) REFERENCES Dersler(DersID)
);
-- Veri ekleme
INSERT INTO Ogrenciler (OgrenciID, Ad) VALUES (1, 'Ali'), (2, 'Zeynep');
INSERT INTO Dersler (DersID, DersAdi) VALUES (101, 'Matematik'), (102, 'Fizik');
INSERT INTO Ogrenci_Ders (OgrenciID, DersID) VALUES (1, 101), (1, 102), (2, 101);
-- Sorgu: Öğrencilerin aldığı dersler
SELECT O.Ad, D.DersAdi
FROM Ogrenciler O
JOIN Ogrenci_Ders OD ON O.OgrenciID = OD.OgrenciID
JOIN Dersler D ON OD.DersID = D.DersID;- Çıktı Örneği:
Ad DersAdi
Ali Matematik
Ali Fizik
Zeynep Matematik- Açıklama:
Ogrenci_Dersara tablosu, N:N ilişkisini yönetir. Her öğrenci birden çok derse, her ders birden çok öğrenciye bağlanabilir.
4. Önemli Noktalar
- Veri Bütünlüğü: Yabancı anahtarlar, referans alınan tablodaki geçerli değerlere işaret etmelidir. Örneğin,
SiparislertablosunaMusteriID=999eklenemez, çünküMusterilertablosunda böyle bir ID yoktur. - Normalizasyon: Tablolar, veri tekrarını önlemek için normalize edilmelidir (ör. 1NF, 2NF, 3NF).
- Performans: Sık sorgulanan sütunlara indeks eklenerek sorgu performansı artırılabilir.
- Kısıtlamalar:
NOT NULL,UNIQUEveCHECKgibi kısıtlamalar veri tutarlılığını sağlar.
Gerçek Dünya Örneği
Bir online kitapçı sisteminde:
- Tablolar:
Kitaplar(KitapID, Başlık, Yazar),Musteriler(MusteriID, Ad, Eposta),Siparisler(SiparisID, MusteriID, KitapID, Tarih). - İlişkiler:
MusterilerveSiparislerarasında 1:N (bir müşteri birden çok sipariş verebilir).KitaplarveSiparislerarasında 1:N (bir kitap birden çok siparişte yer alabilir).- SQL Kullanımı: Yukarıdaki JOIN sorgusu, hangi müşterinin hangi kitabı sipariş ettiğini gösterir.
Birincil anahtarlar, Yabancı anahtarlar ve Benzersiz tanımlayıcılar
1. Birincil Anahtarlar (Primary Key)
Rolü:
- Benzersiz Tanımlama: Bir tablodaki her satırı (kayıt) benzersiz şekilde tanımlar.
- Veri Bütünlüğü: Aynı tablodaki satırların tekrar etmesini önler ve NULL değerleri engeller.
- İlişkisel Bağlantı: Yabancı anahtarlar aracılığıyla diğer tablolarla ilişki kurmak için referans noktasıdır.
Doğru Kullanım Stratejileri:
- Benzersiz ve Anlamlı Seçim: Birincil anahtar, doğal bir benzersiz tanımlayıcı (ör. TC Kimlik No) veya yapay bir kimlik (ör. otomatik artan ID) olabilir. Yapay kimlikler genellikle daha esnek ve güvenlidir.
- Kısa ve Basit Tutma: Performans için birincil anahtar mümkünse tek bir sütun olmalı ve veri tipi (ör. INT) hızlı sorgulamaya uygun olmalıdır.
- Otomatik Artan Değerler:
AUTO_INCREMENTgibi özellikler, benzersiz ID’lerin otomatik oluşturulmasını sağlar. - Değişmezlik: Birincil anahtar değerleri asla değiştirilmemelidir, çünkü bu diğer tablolardaki yabancı anahtarları etkileyebilir.
SQL Örneği:
CREATE TABLE Musteriler (
MusteriID INT PRIMARY KEY AUTO_INCREMENT,
Ad VARCHAR(50) NOT NULL,
Eposta VARCHAR(100)
);Yaygın Hatalar ve Kaçınma Yolları:
- Hata: Anlamsız veya Değişken Değerler Kullanma: Örneğin,
Adgibi sık değişebilen bir sütunu birincil anahtar yapmak. - Çözüm: Değişmeyen, benzersiz bir kimlik (ör.
MusteriID) kullanın. - Hata: Birincil Anahtarı Tanımlamamak: Bu, satırların benzersizliğini garanti etmez.
- Çözüm: Her tabloya bir birincil anahtar tanımlayın.
- Hata: Karmaşık Birleşik Anahtarlar: Birden çok sütundan oluşan birincil anahtarlar, performansı düşürebilir.
- Çözüm: Mümkünse tek sütunlu birincil anahtar tercih edin.
2. Yabancı Anahtarlar (Foreign Key)
Rolü:
- Tablolar Arası İlişki: Bir tablodaki bir sütun, başka bir tablonun birincil anahtarına referans vererek ilişkiler kurar.
- Veri Bütünlüğü: Yabancı anahtar, yalnızca referans tablosunda mevcut olan değerlerin kullanılmasını sağlar (ör. bir sipariş, yalnızca mevcut bir müşteriye bağlanabilir).
- Referans Bütünlüğü: Silme veya güncelleme işlemlerinde veri tutarlılığını korur (ör.
ON DELETE CASCADE).
Doğru Kullanım Stratejileri:
- Doğru Referans Tanımlama: Yabancı anahtar, yalnızca birincil anahtar veya benzersiz anahtar olan bir sütuna referans vermelidir.
- Kısıtlamaları Belirtme:
ON DELETEveON UPDATEgibi kurallar (ör. CASCADE, RESTRICT) ile davranış tanımlanmalıdır. - Performans Optimizasyonu: Yabancı anahtar sütunlarına indeks eklemek, JOIN işlemlerini hızlandırır.
- Gerektiğinde Kapatma: Büyük veri yüklemelerinde geçici olarak yabancı anahtar kısıtlamaları devre dışı bırakılabilir, ancak sonrasında kontrol edilmelidir.
SQL Örneği:
CREATE TABLE Siparisler (
SiparisID INT PRIMARY KEY AUTO_INCREMENT,
MusteriID INT,
SiparisTarihi DATE NOT NULL,
FOREIGN KEY (MusteriID) REFERENCES Musteriler(MusteriID) ON DELETE CASCADE
);- Açıklama:
MusteriID,MusterilertablosununMusteriIDsütununa referans verir. Bir müşteri silinirse, ilgili siparişler de otomatik silinir (ON DELETE CASCADE).
Yaygın Hatalar ve Kaçınma Yolları:
- Hata: Yabancı Anahtar Kısıtlamasını Tanımlamamak: Bu, geçersiz veri girişine (ör. olmayan bir müşteriye sipariş) izin verebilir.
- Çözüm: Her ilişki için yabancı anahtar kısıtlaması tanımlayın.
- Hata: Yanlış Silme/Güncelleme Kuralları: Örneğin,
ON DELETE RESTRICTyerineCASCADEkullanmak, istenmeyen veri kayıplarına neden olabilir. - Çözüm: İş mantığına uygun kural seçin (ör. müşteri silindiğinde siparişlerin korunması gerekiyorsa
RESTRICTkullanın). - Hata: Performans Sorunları: Çok fazla yabancı anahtar, yazma işlemlerini yavaşlatabilir.
- Çözüm: Gerektiğinde yalnızca kritik ilişkiler için yabancı anahtar kullanın ve indeksleme yapın.
3. Benzersiz Tanımlayıcılar (Unique Constraint)
Rolü:
- Benzersizlik Garantisi: Bir sütun veya sütun kombinasyonundaki değerlerin tekrar etmesini önler (ör. e-posta adresleri).
- Alternatif Kimlik: Birincil anahtar dışında, başka bir benzersiz tanımlayıcı olarak kullanılabilir.
- Veri Bütünlüğü: Aynı veri setinde çakışmaları engeller (ör. iki müşterinin aynı e-posta adresine sahip olması).
Doğru Kullanım Stratejileri:
- Doğru Sütun Seçimi: Benzersizlik iş mantığı için kritik olan sütunlara uygulanmalıdır (ör. e-posta, TC Kimlik No).
- NULL Değerlere İzin Verme: Benzersiz kısıtlamalar, NULL değerlere izin verebilir (birincil anahtardan farklı olarak), bu nedenle iş kuralına uygun şekilde tanımlanmalıdır.
- Birleşik Benzersiz Kısıtlamalar: Birden çok sütunun kombinasyonunu benzersiz yapmak için kullanılabilir (ör. şehir ve posta kodu kombinasyonu).
- Performans Düşüncesi: Benzersiz kısıtlamalar, otomatik olarak indeks oluşturur, bu da sorguları hızlandırır.
SQL Örneği:
CREATE TABLE Musteriler (
MusteriID INT PRIMARY KEY AUTO_INCREMENT,
Ad VARCHAR(50) NOT NULL,
Eposta VARCHAR(100) UNIQUE,
TCNo VARCHAR(11) UNIQUE
);- Açıklama:
EpostaveTCNosütunları benzersiz olmalıdır; aynı e-posta veya TC No ile başka bir müşteri eklenemez.
Yaygın Hatalar ve Kaçınma Yolları:
- Hata: Gereksiz Benzersiz Kısıtlamalar: Her sütuna benzersiz kısıtlama eklemek, performansı düşürebilir.
- Çözüm: Yalnızca iş mantığı için gerekli sütunlara uygulayın.
- Hata: Benzersizlik ve NULL Yanılgısı: Benzersiz kısıtlamalı bir sütunda birden fazla NULL değere izin verilmesi, beklenmeyen davranışlara yol açabilir.
- Çözüm: NULL değerlerin iş mantığına etkisini analiz edin ve gerekiyorsa
NOT NULLekleyin. - Hata: Benzersiz Kısıtlamayı Birincil Anahtar ile Karıştırma: Benzersiz kısıtlamalar, birincil anahtar gibi zorunlu bir tanımlayıcı değildir.
- Çözüm: Birincil anahtar için yalnızca bir sütun veya kombinasyon seçin; diğer benzersiz alanlar için
UNIQUEkullanın.
4. Genel Kullanım Stratejileri
- Tutarlı Veri Tipleri: Birincil ve yabancı anahtarlar aynı veri tipine sahip olmalıdır (ör. INT ile INT).
- Dökümantasyon: Anahtarların amacı ve ilişkileri şema dökümantasyonunda açıkça belirtilmelidir.
- Test ve Doğrulama: Anahtar kısıtlamalarının doğru çalıştığından emin olmak için test verileriyle deneme yapılmalıdır.
- Esneklik: Gelecekteki ihtiyaçları karşılamak için anahtar tasarımı modüler ve ölçeklenebilir olmalıdır.
5. Yaygın Hatalardan Kaçınma
- Hata: Anahtarların Eksik Tanımlanması:
- Örnek: Bir tabloya birincil anahtar tanımlamamak, veri tekrarına yol açar.
- Çözüm: Her tabloya birincil anahtar ekleyin ve ilişkiler için yabancı anahtarları unutmayın.
- Hata: Karmaşık Anahtar Tasarımları:
- Örnek: Birden çok sütundan oluşan birincil anahtarlar, bakım ve sorgulamayı zorlaştırır.
- Çözüm: Mümkünse tek sütunlu, otomatik artan kimlikler kullanın.
- Hata: İş Mantığını Göz Ardı Etme:
- Örnek: Benzersiz olması gerekmeyen bir sütuna (ör. telefon numarası) benzersiz kısıtlama eklemek.
- Çözüm: İş gereksinimlerini analiz ederek yalnızca gerekli kısıtlamaları uygulayın.
- Hata: Yabancı Anahtarların Performans Etkisini Görmezden Gelme:
- Örnek: Çok fazla yabancı anahtar, yazma işlemlerini yavaşlatabilir.
- Çözüm: Kritik olmayan ilişkilerde programatik kontroller kullanmayı değerlendirin.
6. Gerçek Dünya Örneği
Bir Online Kitapçı Veritabanı:
- Tablolar:
Kitaplar (KitapID INT PRIMARY KEY, Baslik VARCHAR(100) UNIQUE, Yazar VARCHAR(50))Musteriler (MusteriID INT PRIMARY KEY, Ad VARCHAR(50), Eposta VARCHAR(100) UNIQUE)Siparisler (SiparisID INT PRIMARY KEY, MusteriID INT, KitapID INT, Tarih DATE, FOREIGN KEY (MusteriID) REFERENCES Musteriler(MusteriID), FOREIGN KEY (KitapID) REFERENCES Kitaplar(KitapID))- Açıklama:
KitapIDveMusteriIDbirincil anahtarlar, her satırı benzersiz kılar.BaslikveEpostabenzersiz kısıtlamalara sahip, tekrar eden kitap veya e-posta engellenir.SiparislertablosundaMusteriIDveKitapIDyabancı anahtarlar, yalnızca mevcut müşteri ve kitaplara sipariş verilmesini sağlar.- Hata Örneği: Eğer
Siparislertablosunda yabancı anahtar tanımlanmazsa, olmayan bir müşteriye veya kitaba sipariş eklenebilir. Bu, veri bütünlüğünü bozar.
7. SQL ile Hata Kontrolü Örneği
Yabancı anahtar kısıtlamasının çalıştığını test etmek:
-- Geçersiz bir MusteriID ile sipariş eklemeye çalışma
INSERT INTO Siparisler (SiparisID, MusteriID, SiparisTarihi)
VALUES (101, 999, '2025-05-07');- Hata Mesajı:
FOREIGN KEY constraint failed(ÇünküMusteriID=999mevcut değil).
İndeksler ve kısıtlamalar
1. İndekslerin Veritabanı Performansına Etkisi
İndeks Nedir?
İndeks, bir tablonun belirli sütunlarındaki verilere hızlı erişim sağlamak için oluşturulan bir veri yapısıdır (genellikle B-Tree veya Hash tabanlı). İndeksler, sorguların (özellikle SELECT, WHERE, JOIN) performansını artırır.
Performans Üzerindeki Etkileri:
- Avantajlar:
- Hızlı Veri Erişimi: İndeksler,
WHEREkoşulları,JOINişlemleri ve sıralama (ORDER BY) gibi sorgularda veri tarama süresini azaltır. - Sorgu Optimizasyonu: Örneğin, bir tablodaki
MusteriIDsütununa indeks eklenirse,SELECT * FROM Musteriler WHERE MusteriID = 100sorgusu tam tablo taraması (full table scan) yerine indeks üzerinden çalışır. - Örnek: Bir e-ticaret sisteminde, sık sorgulanan
UrunKodusütununa indeks eklenmesi, ürün aramalarını hızlandırır. - Dezavantajlar:
- Yazma Performansı Azalması:
INSERT,UPDATE,DELETEişlemleri sırasında indekslerin güncellenmesi gerekir, bu da yazma işlemlerini yavaşlatır. - Depolama Alanı: İndeksler ek depolama alanı gerektirir.
- Bakım Yükü: İndekslerin düzenli olarak optimize edilmesi (ör. yeniden oluşturulması) gerekir.
- Örnek: Çok fazla indeks içeren bir tabloya veri eklemek, yazma işlemini ciddi şekilde yavaşlatabilir.
SQL Örneği (İndeks Oluşturma):
-- Musteriler tablosunda Eposta sütununa indeks oluşturma
CREATE INDEX idx_musteri_eposta ON Musteriler(Eposta);
-- İndeksli sorgu
SELECT * FROM Musteriler WHERE Eposta = 'ahmet@example.com';- Açıklama:
idx_musteri_epostaindeksi,Epostaile yapılan sorguları hızlandırır.
2. Kısıtlamaların Veritabanı Performansına Etkisi
Kısıtlamalar Nedir?
Kısıtlamalar (ör. PRIMARY KEY, FOREIGN KEY, UNIQUE, NOT NULL, CHECK), veri bütünlüğünü sağlamak için kullanılan kurallardır.
Performans Üzerindeki Etkileri:
- Avantajlar:
- Veri Bütünlüğü: Kısıtlamalar, yanlış veya tutarsız veri girişini engeller (ör. olmayan bir
MusteriIDile sipariş eklenmesini önler). - Otomatik İndeksleme:
PRIMARY KEYveUNIQUEkısıtlamaları, otomatik olarak indeks oluşturur, bu da sorgu performansını artırır. - Örnek:
UNIQUEkısıtlaması olan birEpostasütunu, aynı e-postanın tekrar eklenmesini engeller ve sorguları hızlandırır. - Dezavantajlar:
- Yazma Performansı Azalması: Kısıtlamalar, her veri yazma işleminde kontrol edilir (ör. yabancı anahtar kontrolü), bu da
INSERTveUPDATEişlemlerini yavaşlatır. - Karmaşıklık Artışı: Çok fazla yabancı anahtar veya karmaşık
CHECKkısıtlamaları, veritabanı işlemlerini karmaşıklaştırabilir. - Örnek: Bir tablodaki çok sayıda yabancı anahtar, toplu veri yüklemelerinde ciddi performans düşüşüne neden olabilir.
SQL Örneği (Kısıtlama Tanımlama):
CREATE TABLE Siparisler (
SiparisID INT PRIMARY KEY,
MusteriID INT,
SiparisTarihi DATE NOT NULL,
FOREIGN KEY (MusteriID) REFERENCES Musteriler(MusteriID),
CONSTRAINT chk_tarih CHECK (SiparisTarihi >= '2020-01-01')
);- Açıklama:
PRIMARY KEYotomatik indeks oluşturur,FOREIGN KEYveri bütünlüğünü sağlar, ancak herINSERTişlemindeMusterilertablosu kontrol edilir.
3. Hangi Durumlarda Ne Tür İndeksleme Kullanılmalı?
İndeks türleri ve kullanım senaryoları şunlardır:
a. B-Tree İndeksi
- Ne Zaman Kullanılır?:
- Genel amaçlı sorgular için (ör.
WHERE,ORDER BY,JOIN). - Aralık sorguları (ör.
WHERE Tarih BETWEEN '2025-01-01' AND '2025-12-31'). - Eşittir karşılaştırmaları (ör.
WHERE MusteriID = 100). - Örnek:
CREATE INDEX idx_siparis_tarihi ON Siparisler(SiparisTarihi);- Avantaj: Çoğu veritabanında varsayılan indeks türüdür, geniş kullanım alanına sahiptir.
- Dezavantaj: Çok büyük veri setlerinde performansı optimize etmek için ek ayarlar gerekebilir.
b. Hash İndeksi
- Ne Zaman Kullanılır?:
- Yalnızca eşittir karşılaştırmaları için (ör.
WHERE UrunKodu = 'ABC123'). - Yüksek hızlı, basit aramalar gereken durumlarda.
- Örnek:
CREATE INDEX idx_urun_kodu_hash ON Urunler(UrunKodu) USING HASH;- Avantaj: Eşittir sorgularında çok hızlıdır.
- Dezavantaj: Aralık sorguları veya sıralama için uygun değildir.
c. Birleşik (Composite) İndeks
- Ne Zaman Kullanılır?:
- Birden çok sütunun birlikte sorgulandığı durumlar (ör.
WHERE MusteriID = 100 AND SiparisTarihi = '2025-05-01'). - Sorgularda sık kullanılan sütun kombinasyonları.
- Örnek:
CREATE INDEX idx_musteri_siparis ON Siparisler(MusteriID, SiparisTarihi);- Avantaj: Çoklu sütun sorgularını hızlandırır.
- Dezavantaj: İndeks sırası önemlidir; yanlış sırada sütun seçimi performansı düşürebilir.
d. Benzersiz (Unique) İndeks
- Ne Zaman Kullanılır?:
- Bir sütunun veya sütun kombinasyonunun benzersiz olması gerektiğinde (ör.
Eposta). - Hem veri bütünlüğü hem de performans artışı sağlar.
- Örnek:
CREATE UNIQUE INDEX idx_unq_eposta ON Musteriler(Eposta);- Avantaj: Tekrar eden verileri engeller ve sorguları hızlandırır.
- Dezavantaj: Yazma işlemlerini yavaşlatabilir.
e. Kısmi (Partial) İndeks
- Ne Zaman Kullanılır?:
- Yalnızca belirli bir veri alt kümesi sık sorgulanıyorsa (ör. yalnızca aktif müşteriler).
- Örnek:
CREATE INDEX idx_aktif_musteriler ON Musteriler(MusteriID) WHERE Durum = 'Aktif';- Avantaj: Daha az depolama alanı kullanır ve performansı artırır.
- Dezavantaj: Yalnızca belirli koşullar için çalışır.
f. Tam Metin (Full-Text) İndeksi
- Ne Zaman Kullanılır?:
- Metin tabanlı aramalar için (ör. ürün açıklamalarında anahtar kelime araması).
- Örnek:
CREATE FULLTEXT INDEX idx_urun_aciklama ON Urunler(Aciklama);
SELECT * FROM Urunler WHERE MATCH(Aciklama) AGAINST('kitap');- Avantaj: Metin aramalarını hızlandırır.
- Dezavantaj: Diğer indeks türlerinden daha fazla kaynak tüketebilir.
4. Optimum İndeks Stratejisi Nasıl Belirlenir?
Optimum indeks stratejisi, veritabanı kullanım desenlerine, iş gereksinimlerine ve performans hedeflerine bağlıdır. Aşağıdaki adımlar izlenmelidir:
a. Sorgu Analizi
- Adım: En sık çalıştırılan sorguları (
SELECT,WHERE,JOIN,GROUP BY,ORDER BY) belirleyin. - Araç:
EXPLAINveyaANALYZEkomutlarıyla sorgu planlarını inceleyin. - Örnek:
EXPLAIN SELECT * FROM Siparisler WHERE MusteriID = 100 AND SiparisTarihi = '2025-05-01';- Strateji: Sık kullanılan
WHEREveJOINsütunlarına indeks ekleyin.
b. İş Yüküne Göre Önceliklendirme
- Oku-Yaz Oranı: Okuma ağırlıklı sistemlerde (ör. raporlama sistemleri) daha fazla indeks kullanılabilir. Yazma ağırlıklı sistemlerde (ör. sipariş girişi) indeks sayısı sınırlanmalıdır.
- Örnek: Bir raporlama sisteminde
SiparisTarihiveMusteriIDiçin birleşik indeks eklemek faydalı olabilir.
c. İndeks Sütun Sırası
- Kural: Birleşik indekslerde, en sık kullanılan sütunlar önce gelmelidir. Örneğin,
WHERE MusteriID = 100 AND SiparisTarihi = '2025-05-01'için indeks(MusteriID, SiparisTarihi)şeklinde olmalıdır. - Örnek:
CREATE INDEX idx_musteri_tarih ON Siparisler(MusteriID, SiparisTarihi);d. Gereksiz İndekslerden Kaçınma
- Adım: Kullanılmayan veya nadiren kullanılan indeksleri düzenli olarak kontrol edin ve kaldırın.
- Araç: Veritabanı yönetim sistemlerinin indeks kullanım istatistiklerini (ör. PostgreSQL’de
pg_stat_user_indexes) kullanın. - Örnek:
DROP INDEX idx_musteri_eposta;e. Performans Testleri
- Adım: İndeks eklemeden önce ve sonra sorgu performansını test edin.
- Araç: Benchmark araçları (ör.
pgbench,sysbench) veya gerçek veri ile test. - Örnek: Bir indeks ekledikten sonra sorgu süresinin 100ms’den 10ms’ye düştüğünü gözlemleyin.
f. Depolama ve Bakım Düşüncesi
- Adım: İndekslerin depolama maliyetini ve bakım yükünü değerlendirin.
- Strateji: Büyük tablolarda yalnızca kritik sütunlara indeks ekleyin ve düzenli olarak indeksleri optimize edin (
REINDEX).
5. Yaygın Hatalar ve Kaçınma Yolları
- Hata: Her Sütuna İndeks Ekleme:
- Sonuç: Yazma performansı düşer, depolama alanı artar.
- Çözüm: Yalnızca sık sorgulanan sütunlara indeks ekleyin.
- Hata: İndeks Sırasını Yanlış Belirleme:
- Sonuç: Birleşik indeksler yanlış sırayla oluşturulursa sorgular optimize olmaz.
- Çözüm: Sorgu desenlerini analiz ederek doğru sütun sırasını belirleyin.
- Hata: Kısıtlamaların Performans Etkisini Görmezden Gelme:
- Sonuç: Çok fazla yabancı anahtar, toplu veri yüklemelerini yavaşlatır.
- Çözüm: Toplu işlemler sırasında kısıtlamaları geçici olarak devre dışı bırakın:
sql ALTER TABLE Siparisler DISABLE CONSTRAINT fk_musteri; -- Veri yükleme ALTER TABLE Siparisler ENABLE CONSTRAINT fk_musteri; - Hata: İndeks Bakımını İhmal Etme:
- Sonuç: Fragmente olmuş indeksler performansı düşürür.
- Çözüm: Düzenli olarak indeksleri yeniden oluşturun:
sql REINDEX TABLE Musteriler;
6. Gerçek Dünya Örneği
Bir E-Ticaret Sistemi:
- Senaryo: Bir e-ticaret platformunda, kullanıcılar sık sık ürün araması (
UrunAdi) ve sipariş geçmişi sorgulaması (MusteriID,SiparisTarihi) yapıyor. - İndeks Stratejisi:
UrunlertablosundaUrunAdiiçin tam metin indeksi:sql CREATE FULLTEXT INDEX idx_urun_adi ON Urunler(UrunAdi);SiparislertablosundaMusteriIDveSiparisTarihiiçin birleşik indeks:sql CREATE INDEX idx_siparis_musteri_tarih ON Siparisler(MusteriID, SiparisTarihi);EpostasütununaUNIQUEkısıtlaması ile otomatik indeks:sql ALTER TABLE Musteriler ADD CONSTRAINT unq_eposta UNIQUE (Eposta);- Sonuç: Ürün aramaları ve sipariş sorguları hızlanır, ancak veri ekleme işlemleri biraz yavaşlar.
- Hata Örneği: Eğer her sütuna indeks eklenirse, sipariş ekleme süresi artar. Bu nedenle yalnızca kritik sütunlara indeks eklenmelidir.
İlişki Türleri
Bire-bir ilişkiler, Bire-çok ilişkiler ve Çoka-çok ilişkiler
1. Bire-Bir (1:1) İlişki
Tanım: Bir tablodaki bir satır, diğer tablodaki yalnızca bir satırla ilişkilidir ve bunun tersi de geçerlidir. Bu ilişki genellikle bir varlığın özelliklerini bölmek için kullanılır.
Kullanım Alanları:
- Verilerin mantıksal olarak ayrılması (ör. güvenlik veya performans nedeniyle).
- Nadiren erişilen ek bilgilerin ayrı bir tabloda saklanması.
- Veritabanı normalizasyonu.
Örnek Senaryo: Bir Kisiler tablosu ve her kişinin yalnızca bir pasaport bilgisi olduğu bir Pasaportlar tablosu.
SQL Uygulaması:
-- Kisiler tablosu
CREATE TABLE Kisiler (
KisiID INT PRIMARY KEY AUTO_INCREMENT,
Ad VARCHAR(50) NOT NULL,
Soyad VARCHAR(50) NOT NULL
);
-- Pasaportlar tablosu (1:1 ilişki)
CREATE TABLE Pasaportlar (
PasaportID INT PRIMARY KEY,
KisiID INT UNIQUE,
PasaportNo VARCHAR(20) NOT NULL,
GecerlilikTarihi DATE,
FOREIGN KEY (KisiID) REFERENCES Kisiler(KisiID)
);
-- Veri ekleme
INSERT INTO Kisiler (Ad, Soyad) VALUES ('Ahmet', 'Yılmaz'), ('Ayşe', 'Kaya');
INSERT INTO Pasaportlar (PasaportID, KisiID, PasaportNo, GecerlilikTarihi)
VALUES (1, 1, 'P123456', '2030-01-01'), (2, 2, 'P789012', '2029-12-31');
-- Sorgu: Kişi ve pasaport bilgilerini birleştirme
SELECT K.Ad, K.Soyad, P.PasaportNo, P.GecerlilikTarihi
FROM Kisiler K
LEFT JOIN Pasaportlar P ON K.KisiID = P.KisiID;Çıktı Örneği:
Ad Soyad PasaportNo GecerlilikTarihi
Ahmet Yılmaz P123456 2030-01-01
Ayşe Kaya P789012 2029-12-31Açıklama:
KisiIDhemKisilertablosunda birincil anahtar hem dePasaportlartablosunda benzersiz bir yabancı anahtar olarak tanımlanmıştır.UNIQUEkısıtlaması, bir kişinin yalnızca bir pasaportunun olmasını sağlar.LEFT JOIN, pasaportu olmayan kişileri de listeler (opsiyonel).
Tasarım Notları:
- 1:1 ilişkilerde genellikle bir tablonun birincil anahtarı, diğer tablonun hem birincil hem de yabancı anahtarı olabilir.
- Performans veya güvenlik nedeniyle (ör. hassas verilerin ayrılması) tercih edilir.
2. Bire-Çok (1:N) İlişki
Tanım: Bir tablodaki bir satır, diğer tablodaki birden çok satırla ilişkilidir, ancak diğer tablodaki bir satır yalnızca bir satırla ilişkilidir. Bu, en yaygın ilişki türüdür.
Kullanım Alanları:
- Hiyerarşik veriler (ör. bir müşteri birden çok sipariş verebilir).
- Gruplanmış veriler (ör. bir departmanda birden çok çalışan).
Örnek Senaryo: Bir Musteriler tablosu ve her müşterinin birden çok siparişi olduğu bir Siparisler tablosu.
SQL Uygulaması:
-- Musteriler tablosu
CREATE TABLE Musteriler (
MusteriID INT PRIMARY KEY AUTO_INCREMENT,
Ad VARCHAR(50) NOT NULL,
Eposta VARCHAR(100) UNIQUE
);
-- Siparisler tablosu (1:N ilişki)
CREATE TABLE Siparisler (
SiparisID INT PRIMARY KEY AUTO_INCREMENT,
MusteriID INT,
SiparisTarihi DATE NOT NULL,
ToplamTutar DECIMAL(10, 2),
FOREIGN KEY (MusteriID) REFERENCES Musteriler(MusteriID)
);
-- Veri ekleme
INSERT INTO Musteriler (Ad, Eposta)
VALUES ('Ali', 'ali@example.com'), ('Zeynep', 'zeynep@example.com');
INSERT INTO Siparisler (MusteriID, SiparisTarihi, ToplamTutar)
VALUES (1, '2025-05-01', 150.50), (1, '2025-05-03', 89.90), (2, '2025-05-04', 200.00);
-- Sorgu: Müşterilerin siparişleriyle birlikte listelenmesi
SELECT M.Ad, M.Eposta, S.SiparisID, S.SiparisTarihi, S.ToplamTutar
FROM Musteriler M
LEFT JOIN Siparisler S ON M.MusteriID = S.MusteriID;Çıktı Örneği:
Ad Eposta SiparisID SiparisTarihi ToplamTutar
Ali ali@example.com 1 2025-05-01 150.50
Ali ali@example.com 2 2025-05-03 89.90
Zeynep zeynep@example.com 3 2025-05-04 200.00Açıklama:
MusteriID,Musterilertablosunda birincil anahtar,Siparislertablosunda ise yabancı anahtardır.- Bir müşteri (
MusteriID=1) birden çok siparişe sahip olabilir, ancak her sipariş yalnızca bir müşteriye aittir. LEFT JOIN, siparişi olmayan müşterileri de listeler.
Tasarım Notları:
- Yabancı anahtar, çok tarafındaki tabloda (ör.
Siparisler) tanımlanır. - İndeksleme,
MusteriIDgibi sık sorgulanan yabancı anahtarlar için performans artırır:
CREATE INDEX idx_siparis_musteri ON Siparisler(MusteriID);3. Çoka-Çok (N:N) İlişki
Tanım: Bir tablodaki birden çok satır, diğer tablodaki birden çok satırla ilişkilidir. Bu ilişki, doğrudan uygulanamaz ve bir junction table (ara tablo) kullanılarak modellenir.
Kullanım Alanları:
- Birden çok varlığın birbirine bağlanması (ör. öğrenciler ve dersler, ürünler ve kategoriler).
- Esnek ve karmaşık ilişkilerin modellenmesi.
Örnek Senaryo: Bir Ogrenciler tablosu ve bir Dersler tablosu. Her öğrenci birden çok derse, her ders birden çok öğrenciye kayıtlı olabilir.
Junction Table (Ara Tablo) Nedir?:
- Çoka-çok ilişkileri yönetmek için kullanılan bir ara tablodur.
- Genellikle iki tablonun birincil anahtarlarını yabancı anahtar olarak içerir.
- Ek öznitelikler (ör. kayıt tarihi) de saklayabilir.
SQL Uygulaması:
-- Ogrenciler tablosu
CREATE TABLE Ogrenciler (
OgrenciID INT PRIMARY KEY AUTO_INCREMENT,
Ad VARCHAR(50) NOT NULL
);
-- Dersler tablosu
CREATE TABLE Dersler (
DersID INT PRIMARY KEY AUTO_INCREMENT,
DersAdi VARCHAR(50) NOT NULL
);
-- Junction table: Ogrenci_Ders
CREATE TABLE Ogrenci_Ders (
OgrenciID INT,
DersID INT,
KayitTarihi DATE,
PRIMARY KEY (OgrenciID, DersID),
FOREIGN KEY (OgrenciID) REFERENCES Ogrenciler(OgrenciID),
FOREIGN KEY (DersID) REFERENCES Dersler(DersID)
);
-- Veri ekleme
INSERT INTO Ogrenciler (Ad) VALUES ('Ali'), ('Zeynep');
INSERT INTO Dersler (DersAdi) VALUES ('Matematik'), ('Fizik');
INSERT INTO Ogrenci_Ders (OgrenciID, DersID, KayitTarihi)
VALUES (1, 1, '2025-01-10'), (1, 2, '2025-01-12'), (2, 1, '2025-01-11');
-- Sorgu: Öğrencilerin aldığı dersler
SELECT O.Ad, D.DersAdi, OD.KayitTarihi
FROM Ogrenciler O
JOIN Ogrenci_Ders OD ON O.OgrenciID = OD.OgrenciID
JOIN Dersler D ON OD.DersID = D.DersID;Çıktı Örneği:
Ad DersAdi KayitTarihi
Ali Matematik 2025-01-10
Ali Fizik 2025-01-12
Zeynep Matematik 2025-01-11Açıklama:
Ogrenci_Dersjunction tablosu,OgrenciIDveDersIDyabancı anahtarlarını içerir.- Birleşik birincil anahtar (
OgrenciID, DersID), aynı öğrenci-ders kombinasyonunun tekrar eklenmesini engeller. KayitTarihigibi ek öznitelikler, ilişkiye özel bilgileri saklar.JOINişlemleri, öğrencilerin hangi derslere kayıtlı olduğunu gösterir.
Junction Table Tasarım Notları:
- Birincil Anahtar: Genellikle junction tablosunda birleşik birincil anahtar (
OgrenciID, DersID) kullanılır. Alternatif olarak, ayrı bir otomatik artan ID de eklenebilir. - Yabancı Anahtarlar: Her iki tablonun birincil anahtarlarına referans verir.
- Ek Öznitelikler: İlişkiye özel veriler (ör. not, kayıt tarihi) junction tablosunda saklanabilir.
- Performans: Yabancı anahtar sütunlarına indeks eklemek,
JOINperformansını artırır:
CREATE INDEX idx_ogrenci_ders ON Ogrenci_Ders(OgrenciID, DersID);4. İlişki Türlerinin Karşılaştırması
| Özellik | Bire-Bir (1:1) | Bire-Çok (1:N) | Çoka-Çok (N:N) |
|---|---|---|---|
| Tanım | Bir satır yalnızca bir satırla ilişkilidir | Bir satır birden çok satırla ilişkilidir | Birden çok satır birden çok satırla ilişkilidir |
| Örnek | Kişi-Pasaport | Müşteri-Sipariş | Öğrenci-Ders |
| Tablo Yapısı | Tek yabancı anahtar, genellikle UNIQUE | Yabancı anahtar çok tarafında | Junction table ile iki yabancı anahtar |
| Kullanım Alanı | Verilerin ayrılması, güvenlik | Hiyerarşik veriler | Karmaşık ilişkiler |
| SQL Kompleksliği | Basit | Orta | Daha karmaşık (JOIN ile) |
5. Junction Table Kullanımının Detayları
Neden Junction Table Gereklidir?:
- Çoka-çok ilişkilerde, iki tabloyu doğrudan bağlamak mümkün değildir çünkü bu, normalizasyon kurallarını ihlal eder ve veri tekrarına yol açar.
- Junction table, bu ilişkiyi normalleştirir ve her bir ilişkiyi ayrı bir satır olarak saklar.
Tasarım İlkeleri:
- Minimal Yapı: Yalnızca gerekli yabancı anahtarlar ve (varsa) ek öznitelikler içermelidir.
- Benzersizlik: Birleşik birincil anahtar veya
UNIQUEkısıtlaması, aynı ilişkinin tekrar eklenmesini önler. - Performans Optimizasyonu: Yabancı anahtar sütunlarına indeks eklenmelidir.
- Esneklik: Ek öznitelikler (ör.
KayitTarihi,Not) ilişkiye özel veriler için kullanılabilir.
Örnek (Ek Öznitelikli Junction Table):
Bir e-ticaret sisteminde ürünler ve kategoriler arasındaki çoka-çok ilişki:
CREATE TABLE Urunler (
UrunID INT PRIMARY KEY AUTO_INCREMENT,
UrunAdi VARCHAR(100) NOT NULL
);
CREATE TABLE Kategoriler (
KategoriID INT PRIMARY KEY AUTO_INCREMENT,
KategoriAdi VARCHAR(50) NOT NULL
);
CREATE TABLE Urun_Kategori (
UrunID INT,
KategoriID INT,
EklenmeTarihi DATE,
PRIMARY KEY (UrunID, KategoriID),
FOREIGN KEY (UrunID) REFERENCES Urunler(UrunID),
FOREIGN KEY (KategoriID) REFERENCES Kategoriler(KategoriID)
);
-- Veri ekleme
INSERT INTO Urunler (UrunAdi) VALUES ('Laptop'), ('Telefon');
INSERT INTO Kategoriler (KategoriAdi) VALUES ('Elektronik'), ('Bilgisayar');
INSERT INTO Urun_Kategori (UrunID, KategoriID, EklenmeTarihi)
VALUES (1, 1, '2025-05-01'), (1, 2, '2025-05-02'), (2, 1, '2025-05-03');
-- Sorgu
SELECT U.UrunAdi, K.KategoriAdi, UK.EklenmeTarihi
FROM Urunler U
JOIN Urun_Kategori UK ON U.UrunID = UK.UrunID
JOIN Kategoriler K ON UK.KategoriID = K.KategoriID;Çıktı Örneği:
UrunAdi KategoriAdi EklenmeTarihi
Laptop Elektronik 2025-05-01
Laptop Bilgisayar 2025-05-02
Telefon Elektronik 2025-05-03Açıklama: Urun_Kategori junction tablosu, bir ürünün birden çok kategoriye ve bir kategorinin birden çok ürüne bağlanmasını sağlar. EklenmeTarihi, ilişkiye özel bir özniteliktir.
6. Yaygın Hatalar ve Kaçınma Yolları
- Hata: 1:1 ve 1:N İçin Gereksiz Junction Table Kullanımı:
- Sonuç: Tasarım karmaşıklaşır ve performans düşer.
- Çözüm: 1:1 için benzersiz yabancı anahtar, 1:N için doğrudan yabancı anahtar kullanın.
- Hata: Junction Table’da Yetersiz Kısıtlamalar:
- Sonuç: Aynı öğrenci-ders kombinasyonunun tekrar eklenmesi.
- Çözüm: Birleşik birincil anahtar veya
UNIQUEkısıtlaması tanımlayın. - Hata: Performans Optimizasyonu Eksikliği:
- Sonuç: Çoklu
JOINişlemleri yavaşlar. - Çözüm: Yabancı anahtar sütunlarına indeks ekleyin.
- Hata: İş Mantığını Yanlış Modelleme:
- Sonuç: Örneğin, bir kişinin birden çok pasaportu olabileceği bir senaryoda 1:1 yerine 1:N kullanmak.
- Çözüm: İş gereksinimlerini dikkatlice analiz edin.
7. Gerçek Dünya Örneği
Bir Eğitim Platformu:
- 1:1: Her öğrencinin bir kullanıcı profili (
KullanicilarveProfiller). - 1:N: Bir öğretmenin birden çok dersi (
OgretmenlerveDersler). - N:N: Öğrencilerin ve derslerin ilişkisi (
Ogrenciler,Dersler,Ogrenci_Dersjunction table). - SQL Tasarımı:
Profiller.KullaniciIDbenzersiz yabancı anahtar ileKullanicilartablosuna bağlanır.Dersler.OgretmenIDyabancı anahtar ileOgretmenlertablosuna bağlanır.Ogrenci_Dersjunction tablosu, öğrencilerin ders kayıtlarını yönetir.
Zorunlu ve isteğe bağlı ilişkiler
Zorunlu İlişkiler
- Tanım: Bir tablodaki bir kaydın, başka bir tablodaki en az bir kayıtla ilişkili olması gerektiği durumlardır. Örneğin, bir
Sipariştablosundaki her kaydın mutlaka birMüşterikaydına bağlı olması zorunlu bir ilişkidir. - Veritabanı Tasarımına Etkisi:
- Yabancı Anahtar Kısıtlamaları: Zorunlu ilişkilerde, yabancı anahtar (foreign key) sütunu NOT NULL olarak tanımlanır. Bu, ilgili tablodaki her kaydın geçerli bir anahtar değerine sahip olmasını zorunlu kılar.
- Veri Bütünlüğü: Zorunlu ilişkiler, veri tutarlılığını sağlar. Örneğin, bir siparişin müşterisiz kaydedilmesi engellenir, bu da veri anomalilerini önler.
- Tasarım Kısıtlamaları: Zorunlu ilişkiler, veri girişini sıkı bir şekilde kontrol eder. Ancak, bu durum esneklik gerektiren senaryolarda (örneğin, bir siparişin henüz bir müşteriye atanmadığı durumlar) tasarımda ek çözümler gerektirebilir.
- Performans: Zorunlu ilişkiler, genellikle birleştirme (join) işlemlerinde daha az NULL kontrolü gerektirir, bu da sorgu performansını artırabilir.
İsteğe Bağlı İlişkiler
- Tanım: Bir tablodaki bir kaydın, başka bir tablodaki bir kayıtla ilişkili olması gerekmediği durumlardır. Örneğin, bir
Çalışantablosunda her çalışanın birYöneticiile ilişkili olması zorunlu olmayabilir. - Veritabanı Tasarımına Etkisi:
- Yabancı Anahtar Esnekliği: İsteğe bağlı ilişkilerde, yabancı anahtar sütunu NULL değer alabilir. Bu, bir kaydın ilgili tabloyla bağlantısı olmayabileceğini gösterir.
- Veri Bütünlüğü: İsteğe bağlı ilişkiler daha esnek bir tasarım sağlar, ancak NULL değerler veri bütünlüğünü karmaşıklaştırabilir. Örneğin, bir sorguda NULL değerlerin yanlış yorumlanması hatalara yol açabilir.
- Tasarım Esnekliği: İsteğe bağlı ilişkiler, uygulama gereksinimlerinde belirsizlik veya eksik veri durumlarını destekler. Örneğin, bir çalışanın yöneticisi henüz atanmamış olabilir.
- Performans: NULL değerlerin varlığı, sorgularda ek kontroller (örneğin,
IS NULLveyaIS NOT NULL) gerektirebilir, bu da performans üzerinde hafif bir etki yaratabilir.
NULL Değerlerin Yönetimi
NULL değerler, isteğe bağlı ilişkilerde sıkça ortaya çıkar ve veritabanı tasarımında dikkatli bir şekilde yönetilmelidir. NULL, bir sütunda veri eksikliğini veya bilinmezliği ifade eder, ancak yanlış kullanıldığında sorgu sonuçlarında hatalara veya beklenmeyen davranışlara neden olabilir.
NULL Değerlerin Yönetiminde Karşılaşılan Zorluklar:
- Anlamsal Belirsizlik: NULL, “veri yok”, “bilinmiyor” veya “geçerli değil” gibi farklı anlamlar taşıyabilir. Bu, uygulama geliştiricilerinin NULL değerleri doğru yorumlamasını zorlaştırır.
- Sorgu Karmaşıklığı: NULL değerler, SQL sorgularında özel işlem gerektirir. Örneğin,
=operatörü yerineIS NULLveyaIS NOT NULLkullanılmalıdır. - Performans Etkisi: NULL değerlerin sık kullanımı, indeksleme ve sorgu optimizasyonunu olumsuz etkileyebilir.
- Veri Bütünlüğü Sorunları: NULL değerlerin yanlış kullanımı, veri tutarlılığını bozabilir. Örneğin, bir sütunda NULL yerine varsayılan bir değer kullanılması daha uygun olabilir.
NULL Değerlerin Yönetiminde En İyi Uygulamalar:
NULL Kullanımını Minimize Edin:
- Mümkünse, NULL yerine varsayılan değerler (default values) kullanın. Örneğin, bir
Durumsütunu için NULL yerine “Bilinmiyor” veya “Yok” gibi bir değer tanımlayın. - Zorunlu ilişkileri tercih ederek NULL kullanımını azaltın, ancak bu karar uygulama gereksinimlerine uygun olmalıdır.
Anlamı Netleştirin:
- NULL’un neyi ifade ettiğini tasarım aşamasında belgeleyin. Örneğin, bir
YöneticiIDsütununda NULL, “çalışanın yöneticisi yok” mu yoksa “yönetici bilgisi bilinmiyor” mu anlamına geliyor? Bu, uygulama geliştiricileri için kritik bir bilgidir.
Yabancı Anahtar Kısıtlamalarını Doğru Kullanın:
- İsteğe bağlı ilişkilerde yabancı anahtar sütunlarının NULL alabileceğini unutmayın, ancak bu sütunların veri bütünlüğünü sağlamak için doğru kısıtlamalarla (constraints) tanımlandığından emin olun.
- Zorunlu ilişkilerde
NOT NULLkısıtlamasını kullanarak veri girişinde hata olasılığını azaltın.
Sorgularda NULL Kontrolü Yapın:
- SQL sorgularında NULL değerleri doğru şekilde ele alın. Örneğin, bir birleştirme işleminde (join)
LEFT JOINkullanarak NULL değerleri dahil edebilir veyaCOALESCEfonksiyonuyla NULL değerleri varsayılan bir değere çevirebilirsiniz. - Örnek:
SELECT COALESCE(YoneticiID, 0) AS YoneticiID FROM Calisanlar
İndeksleme ve Performans Optimizasyonu:
- NULL değerler indekslerde yer kaplar ve sorgu performansını etkileyebilir. Sık sorgulanan sütunlarda NULL kullanımını azaltarak indeks verimliliğini artırın.
- Gerekirse, NULL değerleri filtrelemek için partial index (kısmi indeks) gibi gelişmiş indeksleme tekniklerini kullanın.
Veritabanı Normalizasyonunu Gözden Geçirin:
- NULL değerlerin yoğun olduğu bir tasarım, normalizasyon kurallarına uygun olmayabilir. Örneğin, bir tabloda çok sayıda NULL içeren sütunlar varsa, bu verileri ayrı bir tabloya taşımayı düşünün (örneğin, bir
EkBilgilertablosu).
Uygulama Katmanında Kontrol:
- Veritabanı seviyesinde NULL değerlerin yönetimini desteklemek için uygulama katmanında da doğrulama ve hata yönetimi yapın. Örneğin, bir formda kullanıcıdan zorunlu olmayan bir alan boş bırakıldığında, bu durumun NULL olarak kaydedileceğini garanti edin.
Test ve Doğrulama:
- Veritabanı tasarımını test ederken, NULL değerlerin sorgu sonuçları üzerindeki etkisini kontrol edin. Özellikle, birleştirme işlemleri ve toplu veri analizlerinde NULL değerlerin beklenmedik sonuçlara yol açmadığından emin olun.
Örnek Senaryo
Senaryo: Bir veritabanında Musteriler ve Siparisler tabloları var. Her siparişin bir müşteriye bağlı olması zorunlu değil (isteğe bağlı ilişki).
- Tasarım:
SiparislertablosundaMusteriIDsütunu yabancı anahtar olarak tanımlanır ve NULL alabilir.- Şema:
CREATE TABLE Musteriler ( MusteriID INT PRIMARY KEY, Ad VARCHAR(50) ); CREATE TABLE Siparisler ( SiparisID INT PRIMARY KEY, MusteriID INT NULL, FOREIGN KEY (MusteriID) REFERENCES Musteriler(MusteriID) ); - NULL Yönetimi:
- Bir sipariş müşterisiz kaydedilebilir (
MusteriID = NULL). - Sorgu örneği: Müşterisiz siparişleri listelemek için:
sql SELECT * FROM Siparisler WHERE MusteriID IS NULL; - Müşteri bilgisiyle birlikte siparişleri listelemek için
LEFT JOINkullanılır:SELECT s.SiparisID, m.Ad FROM Siparisler s LEFT JOIN Musteriler m ON s.MusteriID = m.MusteriID; - En İyi Uygulama:
- Eğer müşterisiz siparişler nadir bir durumsa,
MusteriIDiçin bir varsayılan değer (örneğin, “Misafir” müşteriye işaret eden birMusteriID) tanımlanabilir. Bu, NULL kullanımını azaltır ve sorguları basitleştirir.
İleri Düzey Kavramlar
Normalleştirme
Normalleştirme prensipleri
Normalleştirme Prensiplerinin Temel Amaçları
- Veri Fazlalığını Azaltmak: Aynı verinin birden fazla yerde saklanmasını önleyerek depolama verimliliğini artırmak.
- Veri Bütünlüğünü Sağlamak: Veri tutarlılığını korumak için bağımlılıkları doğru yönetmek.
- Anomalileri Önlemek: Ekleme (insertion), silme (deletion) ve güncelleme (update) işlemlerinde veri tutarsızlıklarını engellemek.
- Esnek ve Bakımı Kolay Tasarım: Veritabanının gelecekteki değişikliklere uyum sağlayabilmesi için modüler bir yapı oluşturmak.
1. Normal Form (1NF – Birinci Normal Form)
Tanım ve Kurallar:
- Tüm sütunlar atomik (bölünemez) değerler içermelidir, yani bir sütunda birden fazla değer veya liste bulunamaz.
- Her sütun benzersiz bir isme sahip olmalıdır.
- Tabloda yinelenen satırlar (duplicate rows) olmamalıdır; her satır birincil anahtar (primary key) ile benzersiz şekilde tanımlanmalıdır.
- Satır sırası veya sütun sırası önemli değildir.
Neden Gerekli?
- 1NF, verilerin düzenli ve sorgulanabilir bir yapıda olmasını sağlar.
- Atomik değerler, SQL sorgularının daha kolay yazılmasını ve veri işlenmesini sağlar.
- Yinelenen satırların olmaması, veri fazlalığını ve tutarsızlığı önler.
Örnek:
Normalleştirilmemiş Tablo (1NF’ye uymuyor):
| ÖğrenciID | AdSoyad | Dersler |
|---|---|---|
| 1 | Ali Veli | Matematik, Fizik, Kimya |
| 2 | Ayşe Yılmaz | Biyoloji, Kimya |
Sorunlar:
Derslersütunu atomik değil; birden fazla değeri virgülle ayrılmış şekilde içeriyor.- Bu yapıda, belirli bir dersi sorgulamak zor (örneğin, “Kimya alan öğrenciler kimler?”).
- Ders ekleme veya silme işlemleri karmaşık ve hata yapmaya açık.
1NF’ye Uyarlanmış Tablo:
| ÖğrenciID | AdSoyad | Ders |
|---|---|---|
| 1 | Ali Veli | Matematik |
| 1 | Ali Veli | Fizik |
| 1 | Ali Veli | Kimya |
| 2 | Ayşe Yılmaz | Biyoloji |
| 2 | Ayşe Yılmaz | Kimya |
Değişiklikler:
Derslersütunu atomik hale getirildi; her satır tek bir dersi temsil ediyor.- Birincil anahtar olarak
(ÖğrenciID, Ders)kombinasyonu kullanılabilir.
Önlenen Anomaliler:
- Ekleme Anomalisi: Yeni bir ders eklemek için tüm öğrencilerin ders listesini güncellemek gerekmez.
- Silme Anomalisi: Bir öğrencinin bir dersini silmek, diğer derslerini etkilemez.
- Güncelleme Anomalisi: Bir dersin adı değiştiğinde, yalnızca ilgili satır güncellenir.
2. Normal Form (2NF – İkinci Normal Form)
Tanım ve Kurallar:
- Tablo zaten 1NF’de olmalıdır.
- Tüm non-key (anahtar olmayan) sütunlar, birincil anahtarın tamamına fonksiyonel olarak bağımlı olmalıdır. Yani, anahtarın bir alt kümesine bağımlı olmamalıdır (kısmi bağımlılık olmamalıdır).
- Genellikle, bileşik anahtar (composite key) içeren tablolarda uygulanır.
Neden Gerekli?
- 2NF, kısmi bağımlılıkları ortadan kaldırarak veri fazlalığını azaltır.
- Verilerin yalnızca bir kez saklanmasını sağlar, böylece güncelleme işlemleri daha tutarlı olur.
Örnek:
1NF’de Olan Ancak 2NF’ye Uymayan Tablo:
| ÖğrenciID | DersID | DersAdı | Öğretmen |
|---|---|---|---|
| 1 | 101 | Matematik | Ahmet Hoca |
| 1 | 102 | Fizik | Ayşe Hoca |
| 2 | 101 | Matematik | Ahmet Hoca |
Sorunlar:
- Birincil anahtar
(ÖğrenciID, DersID)’dir. DersAdıveÖğretmensütunları yalnızcaDersID’ye bağlıdır, yani anahtarın yalnızca bir kısmına (kısmi bağımlılık).- Bu, veri fazlalığına neden olur (
DersAdıveÖğretmenher ders için tekrarlanır).
2NF’ye Uyarlanmış Tablolar:
- Dersler Tablosu: DersID DersAdı Öğretmen 101 Matematik Ahmet Hoca 102 Fizik Ayşe Hoca
- ÖğrenciDers Tablosu:
ÖğrenciID DersID
1 101
1 102
2 101 Değişiklikler:- Kısmi bağımlılıklar ayrıldı:
DersAdıveÖğretmenyalnızcaDersID’ye bağlı olduğu için ayrı bir tabloda saklandı. ÖğrenciDerstablosu, yalnızca öğrenciler ve dersler arasındaki ilişkiyi tutar.
- Ekleme Anomalisi: Yeni bir ders eklemek için öğrenci kaydı gerekmez; sadece
Derslertablosuna eklenir. - Silme Anomalisi: Bir öğrencinin bir dersi bırakması, dersin bilgilerini (
DersAdı,Öğretmen) silmez. - Güncelleme Anomalisi: Bir dersin öğretmeni değiştiğinde, yalnızca
Derslertablosunda tek bir satır güncellenir, birden fazla satır değil.
- Tablo zaten 2NF’de olmalıdır.
- Tüm non-key sütunlar, birincil anahtara doğrudan bağımlı olmalıdır ve başka bir non-key sütuna bağımlı olmamalıdır (geçişli bağımlılık olmamalıdır).
- 3NF, geçişli bağımlılıkları ortadan kaldırarak veri fazlalığını daha da azaltır.
- Veri tutarlılığını artırır ve güncelleme işlemlerini basitleştirir.
- Birincil anahtar
SiparişID’dir. MüşteriAdıveŞehirsütunlarıMüşteriID’ye bağlıdır, ancakMüşteriIDbir non-key sütundur (geçişli bağımlılık:SiparişID → MüşteriID → MüşteriAdı, Şehir).- Bu, veri fazlalığına neden olur (
MüşteriAdıveŞehirher sipariş için tekrarlanır).
- Müşteriler Tablosu: MüşteriID MüşteriAdı Şehir 101 Ali Veli İstanbul 102 Ayşe Yılmaz Ankara
- Siparişler Tablosu:
SiparişID MüşteriID
1 101
2 102
3 101 Değişiklikler:- Geçişli bağımlılıklar ayrıldı:
MüşteriAdıveŞehiryalnızcaMüşteriID’ye bağlı olduğu için ayrı bir tabloda saklandı. Siparişlertablosu yalnızca sipariş ve müşteri ilişkisini tutar.
- Ekleme Anomalisi: Yeni bir müşteri eklemek için bir sipariş kaydı gerekmez; sadece
Müşterilertablosuna eklenir. - Silme Anomalisi: Bir sipariş silindiğinde, müşteri bilgileri kaybolmaz.
- Güncelleme Anomalisi: Bir müşterinin şehri değiştiğinde, yalnızca
Müşterilertablosunda tek bir satır güncellenir.
- Tablo zaten 3NF’de olmalıdır.
- Her determinant (bir sütunun başka bir sütunu belirlediği durum), bir candidate key (aday anahtar) olmalıdır.
- BCNF, 3NF’den daha katıdır ve bazı özel durumlarda fonksiyonel bağımlılıkları ele alır.
- BCNF, 3NF’nin ele alamadığı bazı bağımlılık anomalilerini giderir.
- Özellikle, birden fazla aday anahtar içeren tablolarda veri bütünlüğünü sağlar.
- Aday anahtarlar:
(ÖğrenciID, DersID)ve(ÖğrenciID, Öğretmen). DersID → Öğretmen(her ders yalnızca bir öğretmen tarafından verilir).- Ancak,
DersIDbir aday anahtar değildir, bu yüzden tablo BCNF’ye uymaz.
ÖğretmenbilgisiDersID’ye bağlı olduğu için veri fazlalığı oluşur.- Bir dersin öğretmeni değiştiğinde, birden fazla satır güncellenmelidir.
- Dersler Tablosu: DersID Öğretmen 101 Ahmet Hoca 102 Ayşe Hoca
- ÖğrenciDers Tablosu:
ÖğrenciID DersID
1 101
1 102
2 101 Değişiklikler:DersID → Öğretmenbağımlılığı ayrı bir tabloda çözüldü.- Tablo, tüm determinantların aday anahtar olduğu bir yapıya getirildi.
- Güncelleme Anomalisi: Bir dersin öğretmeni değiştiğinde, yalnızca
Derslertablosunda tek bir satır güncellenir. - Ekleme/Silme Anomalisi: Ders ve öğretmen bilgileri, öğrenci kayıtlarından bağımsız olarak yönetilebilir.
- Tablo zaten BCNF’de olmalıdır.
- Tablo, çok değerli bağımlılıklar (multi-valued dependencies) içermemelidir. Çok değerli bağımlılık, bir sütunun değerinin başka bir sütunun değerine bağlı olması, ancak bu bağımlılığın fonksiyonel olmaması durumudur.
- 4NF, birden fazla bağımsız çok değerli ilişkinin aynı tabloda saklanmasından kaynaklanan veri fazlalığını ve anomalileri önler.
DersveHobi,ÖğrenciID’ye bağlıdır, ancak birbirinden bağımsızdır (çok değerli bağımlılık:ÖğrenciID →→ Ders | Hobi).- Bu, veri fazlalığına neden olur (aynı ders ve hobi kombinasyonları tekrarlanır).
- ÖğrenciDers Tablosu: ÖğrenciID Ders 1 Matematik 1 Fizik
- ÖğrenciHobi Tablosu:
ÖğrenciID Hobi
1 Futbol
1 Müzik Değişiklikler:- Çok değerli bağımlılıklar ayrı tablolara bölündü.
- Her tablo, bağımsız ilişkileri temsil eder.
- Ekleme Anomalisi: Yeni bir hobi eklemek için ders bilgisi gerekmez.
- Silme Anomalisi: Bir ders silindiğinde, hobi bilgileri kaybolmaz.
- Güncelleme Anomalisi: Bir öğrencinin hobisi değiştiğinde, yalnızca ilgili tablo güncellenir.
- Tablo zaten 4NF’de olmalıdır.
- Tablo, birleştirme bağımlılıkları (join dependencies) içermemelidir. Yani, tablo yalnızca birleştirme yoluyla kayıpsız (lossless) bir şekilde yeniden oluşturulabiliyorsa 5NF’dedir.
- 5NF, bir tablonun birden fazla ilişkisel bağımlılığı aynı anda temsil etmesini önler.
- 5NF, karmaşık ilişkisel bağımlılıkların neden olduğu veri fazlalığını ve anomalileri giderir.
- Genellikle çok nadir durumlarda uygulanır, çünkü çoğu veritabanı 3NF veya 4NF’de yeterince optimize edilmiştir.
- Tablo,
ÇalışanID,ProjeveDepartmanarasındaki ilişkiyi temsil ediyor. - Ancak, bu tablo birleştirme bağımlılığı içeriyor: Örneğin,
ÇalışanID → ProjeveÇalışanID → Departmanilişkileri,Proje → Departmangibi bir bağımlılık yaratabilir. - Bu, gereksiz veri tekrarına ve bakım zorluklarına neden olabilir.
- ÇalışanProje Tablosu: ÇalışanID Proje 1 Proje A 1 Proje B 2 Proje A
- ÇalışanDepartman Tablosu: ÇalışanID Departman 1 IT 2 Pazarlama
- ProjeDepartman Tablosu (gerekirse):
Proje Departman
Proje A IT
Proje A Pazarlama
Proje B IT Değişiklikler:- Birleştirme bağımlılıkları ayrı tablolara bölündü.
- Her tablo, yalnızca bir ilişki türünü temsil eder.
- Ekleme Anomalisi: Yeni bir proje-departman ilişkisi eklemek için çalışan kaydı gerekmez.
- Silme Anomalisi: Bir çalışanın projesi silindiğinde, departman bilgileri kaybolmaz.
- Güncelleme Anomalisi: Bir projenin departmanı değiştiğinde, yalnızca ilgili tablo güncellenir.
- 1NF, verilerin atomik ve düzenli olmasını sağlar, temel sorgulama ve veri tutarlılığı için gereklidir.
- 2NF, kısmi bağımlılıkları gidererek veri fazlalığını azaltır.
- 3NF, geçişli bağımlılıkları ortadan kaldırarak daha fazla optimizasyon sağlar.
- BCNF, özel bağımlılık durumlarını ele alarak veri bütünlüğünü güçlendirir.
- 4NF, çok değerli bağımlılıkları çözerek bağımsız ilişkileri ayırır.
- 5NF, karmaşık birleştirme bağımlılıklarını gidererek en yüksek düzeyde normalizasyon sağlar.
- Aşırı Normalizasyon: 5NF’ye kadar normalleştirme, genellikle karmaşıklık ve performans sorunlarına yol açabilir (örneğin, çok fazla birleştirme işlemi). Çoğu pratik veritabanı tasarımı 3NF veya BCNF’de durur.
- Denormalizasyon: Performans için bazen veri fazlalığı kasıtlı olarak kabul edilir (örneğin, sık sorgulanan veriler için).
- Uygulama Gereksinimlerine Göre Tasarım: Normalleştirme, iş gereksinimlerine ve sorgu performansına göre dengelenmelidir.
- Geçişli bağımlılıklar ayrıldı:
- Kısmi bağımlılıklar ayrıldı:
Denormalizasyon ve performans optimizasyonu
Denormalizasyon Nedir?
Denormalizasyon, normalleştirilmiş (genellikle 3NF veya BCNF’de) bir veritabanında, veri fazlalığını artırarak tabloları birleştirme (join) işlemlerini azaltmak, sorgu performansını iyileştirmek veya uygulama gereksinimlerini karşılamak için yapılan bir tasarım değişikliğidir. Örneğin, sık erişilen verileri tek bir tabloda bir araya getirmek veya hesaplanmış değerleri önbelleğe almak denormalizasyon tekniklerindendir.
Denormalizasyon Ne Zaman Uygulanmalıdır?
Denormalizasyon, aşağıdaki durumlarda düşünülmelidir:
Yüksek Sorgu Performansı Gereksinimleri:
- Çok sayıda birleştirme (join) işlemi, özellikle büyük veri kümelerinde, sorgu performansını ciddi şekilde yavaşlatıyorsa.
- Gerçek zamanlı uygulamalarda (örneğin, e-ticaret platformları, sosyal medya) hızlı yanıt süreleri kritikse.
Sık Erişilen Veriler:
- Belirli veriler sıkça sorgulanıyorsa ve bu verilerin birleştirme işlemleriyle toplanması maliyetliyse.
- Örnek: Bir raporda her zaman müşteri adı ve sipariş toplamı birlikte gerekiyorsa, bu veriler tek bir tabloda saklanabilir.
Okuma Ağırlıklı Sistemler:
- Veritabanında okuma (SELECT) işlemleri, yazma (INSERT, UPDATE, DELETE) işlemlerinden çok daha fazlaysa (örneğin, raporlama veya analiz sistemleri).
- Okuma performansını artırmak için veri fazlalığı tolere edilebilir.
Önceden Hesaplanmış Verilere İhtiyaç:
- Toplamlar, ortalamalar veya diğer hesaplanmış değerler sıkça kullanılıyorsa, bu değerleri her seferinde hesaplamak yerine saklamak performans sağlar.
Uygulama veya Kullanıcı Deneyimi Gereksinimleri:
- Uygulamanın basitliği veya kullanıcı deneyimi, performans veya geliştirme kolaylığı için denormalizasyonu gerektirebilir.
- Örnek: Bir mobil uygulamada, kullanıcı profil bilgilerinin tek bir sorguda alınması gerekiyorsa.
Donanım veya Ölçeklendirme Kısıtlamaları:
- Eğer veritabanı sunucusunun kaynakları sınırlıysa veya ölçeklendirme maliyetliyse, denormalizasyon daha az birleştirme işlemiyle performansı artırabilir.
Not: Denormalizasyon, yazma ağırlıklı sistemlerde (örneğin, sık güncelleme yapılan bir finans sistemi) veya veri bütünlüğünün kritik olduğu durumlarda dikkatle uygulanmalıdır, çünkü veri fazlalığı anomalilere yol açabilir.
Denormalizasyon Nasıl Uygulanmalıdır?
Denormalizasyon, stratejik ve kontrollü bir şekilde uygulanmalıdır. Aşağıdaki teknikler ve adımlar yaygın olarak kullanılır:
Türetik Verilerin Saklanması:
- Hesaplanmış veya özet verileri (örneğin, toplam sipariş tutarı, kullanıcı puanı) ayrı sütunlarda saklayın.
- Örnek: Bir
Siparişlertablosunda her siparişin toplam tutarını hesaplayıp saklamak.
Tabloları Birleştirme:
- Sık kullanılan birleştirme işlemlerini ortadan kaldırmak için ilişkili verileri tek bir tabloda bir araya getirin.
- Örnek:
MüşterilerveSiparişlertablolarını birleştirerek müşteri bilgilerini sipariş tablosuna eklemek.
Önbelleğe Alma (Caching):
- Sık erişilen sorgu sonuçlarını veya verileri önbellek tablolarında saklayın.
- Örnek: Bir rapor için günlük satış toplamlarını ayrı bir tabloda tutmak.
Yinelenen Verilerin Eklenmesi:
- Aynı veriyi birden fazla tabloda saklayarak birleştirme ihtiyacını azaltın.
- Örnek:
MüşteriAdıgibi sık kullanılan bir bilgiyiSiparişlertablosuna eklemek.
Dizin (Index) ve Materyalize Görünümler Kullanımı:
- Denormalizasyona alternatif olarak, materyalize görünümler veya dizinler kullanarak performansı artırabilirsiniz.
- Örnek: Sık sorgulanan bir birleştirme için materyalize bir görünüm oluşturmak.
Denormalizasyonun Kapsamını Sınırlama:
- Yalnızca performans sorunlarının tespit edildiği alanlarda denormalizasyon uygulayın.
- Tüm veritabanını denormalize etmek yerine, yalnızca kritik sorgular için optimize edin.
Adımlar:
- Performans Analizi: Veritabanı sorgularını analiz edin (örneğin, yavaş sorguları veya yüksek CPU kullanımı olan birleştirmeleri tespit edin).
- Gereksinim Belirleme: Hangi verilerin sık erişildiğini ve hangi sorguların optimize edilmesi gerektiğini belirleyin.
- Denormalizasyon Tasarımı: Hangi tabloların birleştirileceği, hangi verilerin kopyalanacağı veya önbelleğe alınacağı kararını verin.
- Veri Bütünlüğü Planı: Denormalize edilen verilerin güncellenmesi için tetikleyici (trigger), prosedür veya uygulama katmanı kontrolleri oluşturun.
- Test ve İzleme: Denormalizasyonun performans kazanımlarını test edin ve veri tutarlılığını izleyin.
Performans Kazanımları ile Veri Bütünlüğü Arasındaki Denge
Denormalizasyon, performans kazanımları sağlarken veri bütünlüğü risklerini artırır. Bu dengeyi kurmak için aşağıdaki stratejiler kullanılabilir:
Veri Bütünlüğünü Sağlamak için Kontroller:
- Tetikleyiciler (Triggers): Denormalize edilen verilerin güncellenmesini otomatikleştirmek için tetikleyiciler kullanın. Örneğin, bir tabloda müşteri adı değiştiğinde, denormalize edilmiş tablolardaki kopyaları güncelleyin.
- Saklı Prosedürler: Veri güncellemelerini merkezi bir prosedürle yöneterek tutarlılığı sağlayın.
- Uygulama Katmanı Kontrolleri: Veritabanı seviyesinde kontrol zor olduğunda, uygulama kodunda veri tutarlılığını sağlayacak doğrulama mekanizmaları ekleyin.
Denormalizasyonu Sınırlı Tutma:
- Yalnızca performans açısından kritik olan alanlarda denormalizasyon yapın. Örneğin, yalnızca en sık kullanılan raporlama sorguları için veri fazlalığı oluşturun.
- Gereksiz denormalizasyon, bakım maliyetlerini artırır ve veri tutarsızlığı riskini yükseltir.
Okuma-Yazma Ayrımı:
- Okuma ağırlıklı sorgular için denormalize edilmiş tablolar veya önbellekler kullanın, ancak yazma işlemleri için normalleştirilmiş yapıyı koruyun.
- Örnek: Raporlama için denormalize edilmiş bir veri ambarı (data warehouse) kullanırken, işlem veritabanını (OLTP) normalleştirilmiş tutmak.
Düzenli Veri Senkronizasyonu:
- Denormalize edilen verilerin periyodik olarak normalleştirilmiş kaynaklarla senkronize edildiğinden emin olun. Örneğin, bir ETL (Extract, Transform, Load) süreciyle veri güncellemelerini otomatikleştirin.
Dokümantasyon ve İzleme:
- Denormalize edilen alanları ve bağımlılıkları belgeleyin. Hangi verilerin kopyalandığını ve nasıl güncellendiğini netleştirin.
- Veri tutarsızlıklarını tespit etmek için izleme araçları kullanın.
Performans Testleri:
- Denormalizasyonun sağladığı performans kazanımlarını ölçün (örneğin, sorgu süreleri, CPU kullanımı). Eğer kazanımlar küçükse, veri bütünlüğü riskleri ağır basabilir.
Gerçek Dünya Senaryoları ve Örnekler
Senaryo 1: E-Ticaret Platformu – Sık Erişilen Ürün Bilgileri
Problem:
- Bir e-ticaret sitesinde, ürün detay sayfaları sıkça görüntüleniyor ve her görüntüleme için
Ürünler,Kategoriler,StokveFiyatlartabloları arasında birleştirme yapılıyor. - Yoğun trafik saatlerinde, bu birleştirmeler veritabanını yavaşlatıyor ve kullanıcı deneyimini olumsuz etkiliyor.
Denormalizasyon Çözümü:
ÜrünlertablosunaKategoriAdı,StokMiktarıveFiyatgibi sık erişilen bilgileri ekleyin.- Örnek:
Normalleştirilmiş Yapı: Ürünler:(ÜrünID, ÜrünAdı, KategoriID)Kategoriler:(KategoriID, KategoriAdı)Stok:(ÜrünID, StokMiktarı)Fiyatlar:(ÜrünID, Fiyat)Denormalize Edilmiş Yapı:Ürünler:(ÜrünID, ÜrünAdı, KategoriAdı, StokMiktarı, Fiyat)
Performans Kazanımı:
- Ürün detay sorguları tek bir tablodan yapılır, birleştirme ihtiyacı ortadan kalkar.
- Sorgu süreleri %50’ye kadar azalabilir, özellikle yüksek trafikli sitelerde kullanıcı deneyimi iyileşir.
Veri Bütünlüğü Yönetimi:
Kategoriler,StokveyaFiyatlartablolarında bir güncelleme olduğunda,Ürünlertablosundaki ilgili sütunları güncellemek için tetikleyiciler veya saklı prosedürler kullanılır.- Örnek Tetikleyici:
CREATE TRIGGER UpdateUrunKategori
AFTER UPDATE ON Kategoriler
FOR EACH ROW
UPDATE Ürünler
SET KategoriAdı = NEW.KategoriAdı
WHERE KategoriAdı = OLD.KategoriAdı;Denge:
- Performans artışı, kullanıcı deneyimi için kritik olduğundan veri fazlalığı tolere edilir.
- Tetikleyiciler ve düzenli senkronizasyon ile veri tutarsızlığı riski en aza indirilir.
Senaryo 2: Raporlama Sistemi – Satış Raporları
Problem:
- Bir perakende zinciri, günlük satış raporları için
Siparişler,Müşteriler,ÜrünlerveSiparişDetaylarıtablolarını birleştiren karmaşık sorgular kullanıyor. - Raporlar, yöneticiler için gerçek zamanlı değil, gecikmeli üretiliyor ve veritabanı performansını düşürüyor.
Denormalizasyon Çözümü:
- Günlük satış verilerini özetleyen bir denormalize tablo (
SatışRaporu) oluşturun. - Örnek:
Normalleştirilmiş Yapı: Siparişler:(SiparişID, MüşteriID, Tarih)Müşteriler:(MüşteriID, MüşteriAdı)SiparişDetayları:(SiparişID, ÜrünID, Miktar, Fiyat)Ürünler:(ÜrünID, ÜrünAdı)Denormalize Edilmiş Yapı:SatışRaporu:(Tarih, MüşteriAdı, ÜrünAdı, ToplamMiktar, ToplamTutar)- Bu tablo, bir ETL süreciyle her gece güncellenir.
Performans Kazanımı:
- Rapor sorguları, birleştirme yerine tek bir tablodan çalışır, bu da sorgu sürelerini %70’e kadar azaltabilir.
- Yöneticiler, gerçek zamanlıya yakın raporlar alabilir.
Veri Bütünlüğü Yönetimi:
SatışRaporutablosu, yalnızca okuma amaçlıdır ve yazma işlemleri normalleştirilmiş tablolarda yapılır.- ETL süreci, veri tutarlılığını sağlamak için kaynak tablolardan doğru verileri çeker.
- Örnek ETL Sorgusu:
INSERT INTO SatışRaporu (Tarih, MüşteriAdı, ÜrünAdı, ToplamMiktar, ToplamTutar)
SELECT s.Tarih, m.MüşteriAdı, u.ÜrünAdı, SUM(sd.Miktar), SUM(sd.Miktar * sd.Fiyat)
FROM Siparişler s
JOIN Müşteriler m ON s.MüşteriID = m.MüşteriID
JOIN SiparişDetayları sd ON s.SiparişID = sd.SiparişID
JOIN Ürünler u ON sd.ÜrünID = u.ÜrünID
GROUP BY s.Tarih, m.MüşteriAdı, u.ÜrünAdı;Denge:
- Raporlama, okuma ağırlıklı olduğu için denormalizasyon idealdir.
- Veri tutarlılığı, ETL sürecinin doğruluğuna bağlıdır; bu nedenle ETL işlemlerinin test edilmesi ve izlenmesi kritik önemdedir.
Senaryo 3: Sosyal Medya Platformu – Kullanıcı Profilleri
Problem:
- Bir sosyal medya uygulamasında, kullanıcı profilleri (
Kullanıcılar,Gönderiler,Takipçiler) sıkça sorgulanıyor ve her profil görüntülemesi birden fazla tabloyu birleştiriyor. - Yüksek kullanıcı trafiği, veritabanını yavaşlatıyor ve mobil uygulama yanıt sürelerini artırıyor.
Denormalizasyon Çözümü:
- Kullanıcı profillerini önbelleğe alan bir denormalize tablo (
KullanıcıProfilleri) oluşturun. - Örnek:
Normalleştirilmiş Yapı: Kullanıcılar:(KullanıcıID, Ad, Soyad, Eposta)Gönderiler:(GönderiID, KullanıcıID, İçerik, Tarih)Takipçiler:(KullanıcıID, TakipçiID)Denormalize Edilmiş Yapı:KullanıcıProfilleri:(KullanıcıID, AdSoyad, GönderiSayısı, TakipçiSayısı, SonGönderi)- Bu tablo, kullanıcı profili her görüntülendiğinde hızlı erişim sağlar.
Performans Kazanımı:
- Profil görüntüleme sorguları tek bir tablodan yapılır, birleştirme maliyeti ortadan kalkar.
- Mobil uygulama yanıt süreleri %60’a kadar iyileşebilir.
Veri Bütünlüğü Yönetimi:
KullanıcıProfilleritablosu, bir önbellek gibi çalışır ve periyodik olarak veya olay bazlı (örneğin, yeni gönderi eklendiğinde) güncellenir.- Olay bazlı güncelleme için tetikleyici:
CREATE TRIGGER UpdateProfilGonderi
AFTER INSERT ON Gönderiler
FOR EACH ROW
UPDATE KullanıcıProfilleri
SET GönderiSayısı = GönderiSayısı + 1,
SonGönderi = NEW.İçerik
WHERE KullanıcıID = NEW.KullanıcıID;Denge:
- Kullanıcı deneyimi için hızlı yanıt süreleri kritik olduğundan, veri fazlalığı kabul edilir.
- Önbellek tablosunun güncellenmesi, uygulama katmanında veya tetikleyicilerle yönetilir, böylece veri tutarsızlığı riski azalır.
Veri Bütünlüğü ve Kısıtlamalar
1. Varlık Bütünlüğü (Entity Integrity)
Tanım:
- Varlık bütünlüğü, bir tablodaki her satırın benzersiz ve tanımlanabilir olmasını sağlar. Bu, genellikle birincil anahtar (primary key) veya benzersiz anahtar (unique key) kısıtlamalarıyla uygulanır.
- Birincil anahtar, bir tablodaki her satırı benzersiz şekilde tanımlar ve NULL değer alamaz.
Neden Gerekli?
- Satırların benzersizliğini garanti ederek veri tekrarını önler.
- Veritabanında her kaydın net bir şekilde tanımlanmasını sağlar, böylece sorgular ve ilişkiler doğru çalışır.
SQL Örneği:
CREATE TABLE Musteriler (
MusteriID INT PRIMARY KEY, -- Birincil anahtar: Benzersiz ve NULL olamaz
Ad VARCHAR(50) NOT NULL,
Soyad VARCHAR(50) NOT NULL
);
-- Başarılı ekleme
INSERT INTO Musteriler (MusteriID, Ad, Soyad) VALUES (1, 'Ali', 'Veli');
-- Hata: Aynı MusteriID ile ekleme yapılamaz (benzersizlik ihlali)
INSERT INTO Musteriler (MusteriID, Ad, Soyad) VALUES (1, 'Ayşe', 'Yılmaz');
-- Hata: MusteriID NULL olamaz (varlık bütünlüğü ihlali)
INSERT INTO Musteriler (Ad, Soyad) VALUES ('Ahmet', 'Kaya');Önlenen Sorunlar:
- Tekrarlanan Kayıtlar: Aynı birincil anahtar değeri ile birden fazla satır eklenmesini engeller.
- Tanımlanamayan Kayıtlar: NULL birincil anahtar değerleri nedeniyle belirsiz satırların oluşmasını önler.
2. Referans Bütünlüğü (Referential Integrity)
Tanım:
- Referans bütünlüğü, bir tablodaki yabancı anahtar (foreign key) değerlerinin, ilgili tablonun birincil anahtar veya benzersiz anahtar değerleriyle uyumlu olmasını sağlar.
- Yabancı anahtar, bir tablodaki bir sütunun başka bir tablonun birincil anahtarına işaret etmesini sağlar ve bu ilişkiyi korumak için kısıtlamalar uygulanır.
Neden Gerekli?
- Tablolar arasındaki ilişkilerin tutarlılığını korur.
- Geçersiz veya “yetim” (orphaned) kayıtların oluşmasını engeller (örneğin, bir siparişin不存在的 bir müşteriye bağlı olması).
SQL Örneği:
CREATE TABLE Siparisler (
SiparisID INT PRIMARY KEY,
MusteriID INT,
SiparisTarihi DATE,
FOREIGN KEY (MusteriID) REFERENCES Musteriler(MusteriID) -- Referans bütünlüğü
);
-- Başarılı ekleme: MusteriID, Musteriler tablosunda mevcut
INSERT INTO Siparisler (SiparisID, MusteriID, SiparisTarihi)
VALUES (1, 1, '2025-05-07');
-- Hata: MusteriID=999, Musteriler tablosunda yok (referans bütünlüğü ihlali)
INSERT INTO Siparisler (SiparisID, MusteriID, SiparisTarihi)
VALUES (2, 999, '2025-05-07');Referans Eylemleri (Referential Actions):
Yabancı anahtar ilişkilerinde, ana tablodaki bir kaydın güncellenmesi veya silinmesi durumunda, bağımlı tablodaki kayıtların nasıl etkileneceğini belirleyen eylemlerdir. SQL’de yaygın eylemler şunlardır:
CASCADE:
- Ana tablodaki bir kaydın silinmesi veya güncellenmesi durumunda, bağımlı tablodaki ilgili kayıtlar da otomatik olarak silinir veya güncellenir.
- Ne Zaman Kullanılır?:
- Bağımlı kayıtların ana kayıt olmadan anlamsız olduğu durumlarda (örneğin, bir müşteriye bağlı siparişler).
- Veri tutarlılığını otomatik olarak korumak için.
- Örnek:
CREATE TABLE Siparisler ( SiparisID INT PRIMARY KEY, MusteriID INT, FOREIGN KEY (MusteriID) REFERENCES Musteriler(MusteriID) ON DELETE CASCADE ON UPDATE CASCADE ); -- Musteriler tablosundan bir müşteri silindiğinde, ilgili siparişler de silinir DELETE FROM Musteriler WHERE MusteriID = 1; -- Siparisler tablosunda MusteriID=1 olan kayıtlar da silinir -- MusteriID güncellendiğinde, Siparisler tablosundaki MusteriID de güncellenir UPDATE Musteriler SET MusteriID = 100 WHERE MusteriID = 1;
SET NULL:
- Ana tablodaki bir kaydın silinmesi veya güncellenmesi durumunda, bağımlı tablodaki yabancı anahtar değeri NULL olarak ayarlanır.
- Ne Zaman Kullanılır?:
- Yabancı anahtar sütununun NULL alması uygun olduğunda (isteğe bağlı ilişkiler).
- Bağımlı kayıtların ana kayıt olmadan da anlamlı olabileceği durumlarda (örneğin, bir siparişin müşterisi bilinmeyebilir).
- Örnek:
CREATE TABLE Siparisler ( SiparisID INT PRIMARY KEY, MusteriID INT NULL, FOREIGN KEY (MusteriID) REFERENCES Musteriler(MusteriID) ON DELETE SET NULL ON UPDATE SET NULL ); -- Musteriler tablosundan bir müşteri silindiğinde, ilgili siparişlerin MusteriID'si NULL olur DELETE FROM Musteriler WHERE MusteriID = 1; -- Siparisler tablosunda MusteriID=1 olan kayıtlar MusteriID=NULL olur
RESTRICT:
- Ana tablodaki bir kaydın silinmesi veya güncellenmesi, bağımlı tablodaki ilgili kayıtlar varsa engellenir.
- Ne Zaman Kullanılır?:
- Ana kaydın silinmesi veya güncellenmesinin bağımlı kayıtları etkilemesi istenmediğinde.
- Veri kaybını önlemek için sıkı kontrol gerektiğinde (örneğin, bir departmanın silinmesi, çalışanlar varsa engellenir).
- Örnek:
CREATE TABLE Siparisler ( SiparisID INT PRIMARY KEY, MusteriID INT, FOREIGN KEY (MusteriID) REFERENCES Musteriler(MusteriID) ON DELETE RESTRICT ON UPDATE RESTRICT ); -- Hata: MusteriID=1, Siparisler tablosunda kullanıldığı için silinemez DELETE FROM Musteriler WHERE MusteriID = 1;
NO ACTION (varsayılan davranış):
- RESTRICT ile benzerdir, ancak bazı veritabanlarında işlem sırası farklı olabilir (örneğin, işlem sonunda kontrol edilir).
- Ne Zaman Kullanılır?: RESTRICT gibi durumlarda, ancak daha fazla esneklik gerektiğinde.
SET DEFAULT:
- Ana tablodaki bir kaydın silinmesi veya güncellenmesi durumunda, bağımlı tablodaki yabancı anahtar varsayılan bir değere ayarlanır.
- Ne Zaman Kullanılır?: Nadiren kullanılır, çünkü yabancı anahtar için uygun bir varsayılan değer tanımlanması zordur.
Referans Eylemlerinin Kullanım Senaryoları:
- CASCADE: Bir e-ticaret sisteminde, bir müşteri hesabını sildiğinde, tüm siparişlerinin de silinmesi isteniyorsa.
- SET NULL: Bir çalışanın bağlı olduğu departman silindiğinde, çalışanın departman bilgisinin NULL olması kabul edilebilirse.
- RESTRICT: Bir okul veritabanında, bir dersin silinmesi, o derse kayıtlı öğrenciler varsa engellenmek isteniyorsa.
Önlenen Sorunlar:
- Yetim Kayıtlar: Yabancı anahtarların geçersiz değerler (var olmayan birincil anahtarlar) almasını engeller.
- Veri Tutarsızlığı: Tablolar arasındaki ilişkilerin bozulmasını önler.
3. Alan Kısıtlamaları (Domain Constraints)
Tanım:
- Alan kısıtlamaları, bir sütunun alabileceği değerlerin türünü, aralığını veya biçimini sınırlandırır. Bu, veri doğruluğunu ve uygunluğunu sağlar.
- Yaygın alan kısıtlamaları: NOT NULL, CHECK, DEFAULT, veri türü kısıtlamaları ve UNIQUE.
Neden Gerekli?
- Verilerin belirli kurallara uygun olmasını sağlar (örneğin, yaşın negatif olmaması).
- Uygulama seviyesinde doğrulama yükünü azaltır ve veritabanı seviyesinde tutarlılık sağlar.
SQL Örneği:
CREATE TABLE Calisanlar (
CalisanID INT PRIMARY KEY,
Ad VARCHAR(50) NOT NULL, -- NOT NULL: Ad boş olamaz
Yas INT CHECK (Yas >= 18 AND Yas <= 65), -- CHECK: Yaş 18-65 aralığında olmalı
Departman VARCHAR(50) DEFAULT 'Belirtilmemiş', -- DEFAULT: Varsayılan değer
Email VARCHAR(100) UNIQUE -- UNIQUE: E-posta benzersiz olmalı
);
-- Başarılı ekleme
INSERT INTO Calisanlar (CalisanID, Ad, Yas, Email)
VALUES (1, 'Ali', 30, 'ali@example.com');
-- Hata: Ad NULL olamaz
INSERT INTO Calisanlar (CalisanID, Yas, Email)
VALUES (2, 25, 'ayse@example.com');
-- Hata: Yas 18-65 aralığında değil
INSERT INTO Calisanlar (CalisanID, Ad, Yas, Email)
VALUES (3, 'Ayşe', 17, 'ayse@example.com');
-- Hata: E-posta zaten kullanılıyor
INSERT INTO Calisanlar (CalisanID, Ad, Yas, Email)
VALUES (4, 'Ahmet', 40, 'ali@example.com');
-- Varsayılan değer kullanımı
INSERT INTO Calisanlar (CalisanID, Ad, Yas, Email)
VALUES (5, 'Veli', 35, 'veli@example.com'); -- Departman: 'Belirtilmemiş'Önlenen Sorunlar:
- Geçersiz Veriler: Yaşın negatif olması veya e-postanın tekrarlanması gibi hataları önler.
- Eksik Veriler: Zorunlu alanların (NOT NULL) boş bırakılmasını engeller.
- Tutarlılık: Verilerin tanımlı kurallara uygun olmasını sağlar.
Referans Eylemlerinin Ne Zaman Kullanılacağına Dair Özet
| Eylem | Kullanım Senaryosu | Örnek Durum |
|---|---|---|
| CASCADE | Ana kaydın silinmesi/güncellenmesi bağımlı kayıtları da etkilemeli. | Bir müşterinin silinmesiyle siparişlerinin de silinmesi. |
| SET NULL | Ana kaydın silinmesi/güncellenmesi durumunda bağımlı kayıtlar NULL olabilir. | Bir departman silindiğinde, çalışanların departman bilgisinin NULL olması. |
| RESTRICT | Ana kaydın silinmesi/güncellenmesi, bağımlı kayıtlar varsa engellenmeli. | Bir dersin silinmesi, kayıtlı öğrenciler varsa engellenir. |
| NO ACTION | RESTRICT ile benzer, ancak işlem sırası farklı olabilir. | RESTRICT’e benzer, ancak daha esnek işlem sıraları için. |
| SET DEFAULT | Bağımlı kayıtların yabancı anahtarı varsayılan bir değere ayarlanmalı (nadir kullanılır). | Bir kategorinin silinmesiyle, ürünlerin varsayılan bir kategoriye atanması. |
Pratik Uygulama ve Dikkat Edilmesi Gerekenler
Performans Etkisi:
- CASCADE ve SET NULL, ek işlemler (silme/güncelleme) gerektirdiğinden performansı etkileyebilir. Büyük veri kümelerinde dikkatli kullanılmalıdır.
- RESTRICT, silme/güncelleme işlemlerini engelleyerek performansı etkilemez, ancak uygulama mantığında ek kontroller gerektirebilir.
Uygulama Gereksinimlerine Göre Seçim:
- İş mantığına göre hangi eylemin uygun olduğuna karar verilmelidir. Örneğin, bir muhasebe sisteminde RESTRICT tercih edilerek veri kaybı önlenirken, bir sosyal medya uygulamasında CASCADE ile hızlı temizlik yapılabilir.
Dokümantasyon:
- Hangi tablolarda hangi referans eylemlerinin kullanıldığı belgelenmelidir. Bu, bakım ve hata ayıklama süreçlerini kolaylaştırır.
Test ve Doğrulama:
- Referans eylemlerinin doğru çalıştığından emin olmak için test senaryoları oluşturulmalıdır (örneğin, bir müşteri silindiğinde siparişlerin durumu kontrol edilmelidir).
Şema Tasarımı
Şema tasarım prensipleri ve Çok katmanlı şema yapıları
Şema Tasarım Prensipleri
Şema, bir veritabanındaki tablolar, sütunlar, ilişkiler, kısıtlamalar ve diğer yapısal bileşenlerin tanımlandığı bir yapıdır. Şema tasarımı, veritabanının iş gereksinimlerini karşılayacak şekilde düzenlenmesini sağlar. Temel şema tasarım prensipleri şunlardır:
Veri Bütünlüğü ve Tutarlılık:
- Varlık Bütünlüğü: Her tablo, benzersiz bir birincil anahtar (primary key) ile tanımlanmalıdır. Bu, satırların benzersizliğini garanti eder.
- Referans Bütünlüğü: Yabancı anahtarlar (foreign keys), ilişkili tablolar arasında tutarlılığı sağlar.
- Alan Kısıtlamaları: Veri türleri, NOT NULL, CHECK ve DEFAULT gibi kısıtlamalar, verilerin doğruluğunu ve uygunluğunu korur.
Normalizasyon:
- Veritabanı, genellikle 3NF (üçüncü normal form) veya BCNF seviyesinde normalize edilmelidir. Bu, veri fazlalığını (redundancy) azaltır ve ekleme, silme, güncelleme anomalilerini önler.
- Örnek: Bir
Müşterilertablosunda müşteri bilgileri ayrı,Siparişlertablosunda sipariş bilgileri ayrı tutulur.
Performans Optimizasyonu:
- Normalizasyon, veri bütünlüğünü sağlasa da, aşırı normalizasyon performans sorunlarına yol açabilir. Bu nedenle, denormalizasyon stratejik olarak uygulanabilir (örneğin, sık sorgulanan verileri birleştirme işlemini azaltmak için).
- Dizinler (indexes), sorgu performansını artırmak için kritik öneme sahiptir, ancak yazma işlemlerini yavaşlatabilir.
Esneklik ve Ölçeklenebilirlik:
- Şema, gelecekteki değişikliklere (örneğin, yeni özellikler veya veri türleri ekleme) uyum sağlayacak şekilde tasarlanmalıdır.
- Büyük ölçekli sistemlerde, şema modüler olmalı ve farklı iş birimlerine veya modüllere ayrılabilmelidir.
Anlaşılırlık ve Bakım Kolaylığı:
- Tablo ve sütun isimleri, iş mantığını yansıtacak şekilde anlamlı ve tutarlı olmalıdır (örneğin,
MusteriIDyerineCustomerIDgibi standart isimlendirme). - Şema dokümantasyonu, tabloların amacı, ilişkiler ve kısıtlamalar hakkında net bilgiler içermelidir.
Güvenlik ve Erişim Kontrolü:
- Şema, veri erişimini kısıtlamak için roller ve izinlerle (permissions) yapılandırılmalıdır.
- Hassas veriler (örneğin, kişisel bilgiler) ayrı tablolarda veya şifrelenmiş olarak saklanabilir.
Veri Türü ve Depolama Optimizasyonu:
- Her sütun, uygun veri türüyle tanımlanmalıdır (örneğin, tarih için
DATE, sayılar içinINTveyaDECIMAL). - Depolama maliyetlerini azaltmak için veri türleri optimize edilmelidir (örneğin, küçük sayılar için
SMALLINTyerineINTkullanmaktan kaçının).
Çok Katmanlı Şema Yapıları
Çok katmanlı şema yapıları, veritabanı tasarımını kavramsal, mantıksal ve fiziksel seviyelerde organize etmek için kullanılan bir yaklaşımdır. Bu yapı, veritabanı tasarımını daha anlaşılır ve yönetilebilir hale getirir. Üç temel katman şunlardır:
Kavramsal Şema (Conceptual Schema):
- Tanım: Veritabanının yüksek seviyeli, iş odaklı bir modelidir. İş gereksinimlerini ve varlık ilişkilerini (entities and relationships) tanımlar.
- Amaç: İş mantığını soyut bir şekilde ifade eder, teknik detaylara girmez.
- Örnek: Bir e-ticaret sistemi için kavramsal şema,
Müşteriler,Siparişler,Ürünlergibi varlıkları ve aralarındaki ilişkileri (örneğin, “bir müşteri birden fazla sipariş verebilir”) tanımlar. - Araçlar: ER (Entity-Relationship) diyagramları genellikle kullanılır.
- Örnek ER Diyagramı:
[Müşteriler] ---1:N---> [Siparişler] ---N:M---> [Ürünler]
Mantıksal Şema (Logical Schema):
- Tanım: Kavramsal şemayı, belirli bir veritabanı yönetim sistemi (DBMS) için uygulanabilir bir yapıya dönüştürür. Tablolar, sütunlar, veri türleri, birincil/yabancı anahtarlar ve kısıtlamalar tanımlanır.
- Amaç: Veritabanının yapısını, DBMS’ye özgü olmadan soyut bir şekilde tanımlar.
- Örnek:
Müşterilertablosu içinMusteriID (INT, PRIMARY KEY),Ad (VARCHAR),Siparişlertablosu içinSiparisID (INT, PRIMARY KEY),MusteriID (FOREIGN KEY)gibi tanımlar. - SQL Örneği:
CREATE TABLE Musteriler ( MusteriID INT PRIMARY KEY, Ad VARCHAR(50) NOT NULL, Soyad VARCHAR(50) NOT NULL ); CREATE TABLE Siparisler ( SiparisID INT PRIMARY KEY, MusteriID INT, SiparisTarihi DATE, FOREIGN KEY (MusteriID) REFERENCES Musteriler(MusteriID) );
Fiziksel Şema (Physical Schema):
- Tanım: Veritabanının fiziksel depolama yapısını tanımlar. Dizinler, bölümleme (partitioning), dosya grupları, depolama motorları ve performans optimizasyonları bu katmanda belirlenir.
- Amaç: Veritabanının performansını, ölçeklenebilirliğini ve depolama verimliliğini optimize eder.
- Örnek:
Musterilertablosu için birINDEXoluşturma, tabloyu yıllara göre bölümleme veya belirli bir depolama motoru (örneğin, InnoDB veya MyISAM) seçme. - SQL Örneği:
CREATE INDEX idx_musteri_ad ON Musteriler(Ad); -- Performans için dizin CREATE TABLE Siparisler ( SiparisID INT PRIMARY KEY, MusteriID INT, SiparisTarihi DATE, FOREIGN KEY (MusteriID) REFERENCES Musteriler(MusteriID) ) PARTITION BY RANGE (YEAR(SiparisTarihi)) ( PARTITION p2023 VALUES LESS THAN (2024), PARTITION p2024 VALUES LESS THAN (2025), PARTITION p2025 VALUES LESS THAN (2026) );
Çok Katmanlı Şema Yapısının Avantajları:
- Soyutlama: Kavramsal katman, iş mantığını teknik detaylardan ayırır.
- Esneklik: Mantıksal şema, farklı DBMS’lere uyarlanabilir.
- Optimizasyon: Fiziksel şema, performansı ve depolamayı optimize eder.
- Bakım Kolaylığı: Her katman ayrı ayrı yönetilebilir, değişiklikler daha kolay uygulanır.
Büyük Ölçekli Veritabanında Şema Organizasyonu
Büyük ölçekli veritabanları (örneğin, milyonlarca kaydı veya terabaytlarca veriyi yöneten sistemler), yüksek trafik, karmaşık iş mantığı ve ölçeklenebilirlik gereksinimleriyle karşı karşıyadır. Bu tür sistemlerde şema organizasyonu, aşağıdaki prensipler ve uygulamalar doğrultusunda yapılmalıdır:
1. Modüler ve İşlevsel Ayrım
- Modüler Tablolar: Veritabanını işlevsel modüllere ayırın (örneğin, müşteri yönetimi, sipariş yönetimi, envanter yönetimi).
- Şema Ayrımı: Büyük sistemlerde, her modül için ayrı bir şema (schema) veya veritabanı kullanılabilir. Örneğin:
crmşeması: Müşteri bilgileri ve iletişim.ordersşeması: Siparişler ve ödemeler.inventoryşeması: Ürün ve stok bilgileri.- SQL Örneği:
CREATE SCHEMA crm;
CREATE TABLE crm.Musteriler (
MusteriID INT PRIMARY KEY,
Ad VARCHAR(50)
);
CREATE SCHEMA orders;
CREATE TABLE orders.Siparisler (
SiparisID INT PRIMARY KEY,
MusteriID INT,
FOREIGN KEY (MusteriID) REFERENCES crm.Musteriler(MusteriID)
);2. Normalizasyon ve Denormalizasyon Dengesi
- Normalizasyon: Çekirdek işlem veritabanları (OLTP) için genellikle 3NF seviyesinde normalizasyon tercih edilir. Bu, veri tutarlılığını ve yazma işlemlerini optimize eder.
- Denormalizasyon: Raporlama veya analitik sistemler (OLAP) için denormalize edilmiş tablolar veya veri ambarları (data warehouses) kullanılır. Örneğin, sık erişilen müşteri ve sipariş bilgilerini birleştiren bir tablo.
- Örnek: Bir e-ticaret sisteminde,
SiparisRaporutablosu denormalize edilerek müşteri adı ve sipariş toplamı gibi bilgiler tek bir tabloda saklanabilir:
CREATE TABLE SiparisRaporu (
SiparisID INT,
MusteriAd VARCHAR(100),
ToplamTutar DECIMAL(10,2),
SiparisTarihi DATE
);3. Bölümleme (Partitioning) ve Sharding
- Bölümleme: Büyük tablolar, mantıksal parçalara bölünerek performans artırılır. Örneğin,
Siparislertablosu yıllara veya bölgelere göre bölünür. - SQL Örneği:
sql CREATE TABLE Siparisler ( SiparisID INT, MusteriID INT, SiparisTarihi DATE ) PARTITION BY RANGE (YEAR(SiparisTarihi)) ( PARTITION p2023 VALUES LESS THAN (2024), PARTITION p2024 VALUES LESS THAN (2025) ); - Sharding: Veriler fiziksel olarak farklı veritabanı sunucularına dağıtılır (örneğin, coğrafi bölgelere göre). Bu, ölçeklenebilirliği artırır, ancak şema yönetimini karmaşıklaştırır.
- Örnek: Avrupa müşterileri için bir veritabanı, Asya müşterileri için başka bir veritabanı.
4. Dizinleme Stratejisi
- Sık sorgulanan sütunlar için dizinler oluşturun, ancak aşırı dizinleme yazma performansını düşürebilir.
- Örnek:
CREATE INDEX idx_siparis_tarihi ON Siparisler(SiparisTarihi);
CREATE INDEX idx_musteri_ad ON Musteriler(Ad);- Kapsayıcı Dizinler (Covering Indexes): Sorguların tamamını karşılayacak dizinler oluşturun.
CREATE INDEX idx_siparis_musteri ON Siparisler(MusteriID, SiparisTarihi);5. Veri Türü ve Depolama Optimizasyonu
- Sütunlar için uygun veri türleri seçin (örneğin,
BIGINTyerineINTveyaVARCHAR(50)yerineCHAR(10)). - Büyük veri kümeleri için sıkıştırma (compression) veya columnar storage gibi teknolojiler kullanın (örneğin, PostgreSQL’de
TOASTveya Snowflake’ta columnar storage).
6. Güvenlik ve Erişim Kontrolü
- Her şema veya tablo için uygun izinler tanımlayın.
- Hassas verileri (örneğin, kredi kartı bilgileri) şifrelenmiş sütunlarda saklayın.
- SQL Örneği:
GRANT SELECT, INSERT ON crm.Musteriler TO 'crm_user';
REVOKE DELETE ON orders.Siparisler FROM 'public';7. Veri Arşivleme ve Temizleme
- Eski verileri arşivlemek için ayrı tablolar veya veritabanları kullanın. Örneğin, 5 yıldan eski siparişler bir
SiparisArsivtablosuna taşınabilir. - SQL Örneği:
INSERT INTO SiparisArsiv
SELECT * FROM Siparisler WHERE SiparisTarihi < '2020-01-01';
DELETE FROM Siparisler WHERE SiparisTarihi < '2020-01-01';8. Şema Versiyonlama ve Göç (Migration)
- Büyük ölçekli sistemlerde, şema değişiklikleri (örneğin, yeni sütun ekleme) dikkatle yönetilmelidir. Şema versiyonlama araçları (örneğin, Flyway, Liquibase) kullanılabilir.
- Örnek: Yeni bir sütun ekleme:
ALTER TABLE Musteriler ADD Telefon VARCHAR(15);9. Performans İzleme ve Optimizasyon
- Sorgu performansını izlemek için araçlar (örneğin, PostgreSQL’de
EXPLAIN ANALYZE, Oracle’da AWR raporları) kullanın. - Yavaş sorgular için dizin ekleme, bölümleme veya denormalizasyon gibi çözümler uygulayın.
10. Dokümantasyon ve Standartlar
- Her tablo, sütun ve ilişkinin amacı dokümante edilmelidir.
- İsimlendirme standartları tutarlı olmalıdır (örneğin,
IDyerineMusteriID, tablo isimleri çoğul:Musteriler,Siparisler). - Örnek Dokümantasyon:
Tablo: Musteriler
- MusteriID (INT, PRIMARY KEY): Benzersiz müşteri kimliği
- Ad (VARCHAR): Müşterinin adı
- Soyad (VARCHAR): Müşterinin soyadı
İlişkiler: Siparisler.MusteriID ile 1:N ilişkisiBüyük Ölçekli Veritabanında Şema Organizasyonu için Örnek
Bir e-ticaret platformu için büyük ölçekli bir veritabanı şema organizasyonu şu şekilde olabilir:
Şema Ayrımı:
crm: Müşteri bilgileri, iletişim geçmişi, destek talepleri.orders: Siparişler, ödemeler, iade işlemleri.inventory: Ürünler, stok, tedarikçiler.analytics: Raporlama ve analitik veriler (denormalize edilmiş).
Tablo Örneği:
-- CRM Şeması
CREATE SCHEMA crm;
CREATE TABLE crm.Musteriler (
MusteriID BIGINT PRIMARY KEY,
Ad VARCHAR(50) NOT NULL,
Soyad VARCHAR(50) NOT NULL,
Email VARCHAR(100) UNIQUE,
KayitTarihi DATE DEFAULT CURRENT_DATE
);
-- Orders Şeması
CREATE SCHEMA orders;
CREATE TABLE orders.Siparisler (
SiparisID BIGINT PRIMARY KEY,
MusteriID BIGINT,
SiparisTarihi DATE,
ToplamTutar DECIMAL(10,2),
FOREIGN KEY (MusteriID) REFERENCES crm.Musteriler(MusteriID) ON DELETE SET NULL
) PARTITION BY RANGE (SiparisTarihi);
-- Inventory Şeması
CREATE SCHEMA inventory;
CREATE TABLE inventory.Urunler (
UrunID BIGINT PRIMARY KEY,
UrunAdi VARCHAR(100),
KategoriID INT,
StokMiktari INT CHECK (StokMiktari >= 0)
);
-- Analytics Şeması (Denormalize)
CREATE SCHEMA analytics;
CREATE TABLE analytics.SiparisRaporu (
SiparisID BIGINT,
MusteriAd VARCHAR(100),
UrunAdi VARCHAR(100),
ToplamTutar DECIMAL(10,2),
SiparisTarihi DATE
);Performans Optimizasyonları:
Siparislertablosu için tarih bazlı bölümleme.Musteriler.EmailveSiparisler.SiparisTarihiiçin dizinler.SiparisRaporutablosu, ETL süreciyle periyodik olarak güncellenir.
Güvenlik:
crm.Musterilertablosuna yalnızca CRM ekibi erişebilir.analyticsşemasına yalnızca raporlama araçları erişir.
Arşivleme:
- 3 yıldan eski siparişler,
orders.SiparisArsivtablosuna taşınır.
Şema versiyonlama ve evrim
Şema Versiyonlama ve Evrimi Nedir?
- Şema Versiyonlama: Veritabanı şemasının (tablolar, sütunlar, kısıtlamalar, dizinler vb.) her bir durumunun bir sürüm numarası veya kimliğiyle takip edilmesidir. Her değişiklik, şemanın yeni bir versiyonunu oluşturur.
- Şema Evrimi: Zamanla iş gereksinimlerine veya teknik ihtiyaçlara bağlı olarak şemada yapılan değişikliklerdir. Örneğin, yeni bir sütun ekleme, bir tabloyu yeniden yapılandırma veya kısıtlamaları güncelleme.
Neden Önemli?
- Canlı sistemlerde, şema değişiklikleri yanlış uygulanırsa veri kaybına, uygulama hatalarına veya kesintilere neden olabilir.
- Şema versiyonlama, değişikliklerin izlenebilir, tekrarlanabilir ve geri alınabilir olmasını sağlar.
- Büyük ekiplerde, birden fazla geliştiricinin aynı şema üzerinde çalışması durumunda çakışmaları önler.
Şema Versiyonlama ve Evrimi için En İyi Pratikler
Şema Değişikliklerini Kod Olarak Yönetin (Database as Code):
- Şema değişikliklerini SQL betikleri (scripts) veya yapılandırma dosyaları olarak saklayın ve bunları bir sürüm kontrol sistemine (örneğin, Git) entegre edin.
- Her değişiklik, bir migration (göç) dosyası olarak tanımlanır ve sırasıyla uygulanır.
- Örnek: Bir sütun ekleme için migration dosyası:
sql -- migration_20250507_add_email.sql ALTER TABLE Musteriler ADD Email VARCHAR(100);
Migration Araçları Kullanın:
- Şema değişikliklerini otomatikleştirmek ve yönetmek için migration araçları kullanın. Popüler araçlar:
- Flyway: SQL veya Java tabanlı migration’lar için.
- Liquibase: XML, YAML veya SQL ile şema değişikliklerini tanımlar.
- Alembic: Python tabanlı, özellikle SQLAlchemy ile kullanılır.
- Bu araçlar, şema değişikliklerini sıralı bir şekilde uygular, versiyonları takip eder ve çakışmaları önler.
- Örnek (Flyway):
-- V1__create_musteriler.sql CREATE TABLE Musteriler ( MusteriID INT PRIMARY KEY, Ad VARCHAR(50) ); -- V2__add_email.sql ALTER TABLE Musteriler ADD Email VARCHAR(100);
Artımlı ve Geri Alınabilir Değişiklikler:
- Her migration, küçük ve artımlı değişiklikler içermeli. Büyük çaplı yeniden yapılandırmalar yerine küçük adımlarla ilerleyin.
- Her migration için bir geri alma (rollback) betiği hazırlayın. Örneğin:
-- Uygulama (up) ALTER TABLE Musteriler ADD Telefon VARCHAR(15); -- Geri alma (down) ALTER TABLE Musteriler DROP COLUMN Telefon; - Geri alma betikleri, özellikle test ortamlarında veya hata durumlarında kullanışlıdır.
Şema Versiyonlarını Tutarlı Şekilde Numaralandırın:
- Migration dosyalarına sıralı ve benzersiz bir kimlik verin (örneğin,
V1,V2veya zaman damgası:202505071200). - Zaman damgaları, çakışmaları önlemek için özellikle büyük ekiplerde kullanışlıdır.
- Örnek:
20250507_01_add_email.sql,20250507_02_add_index.sql.
Değişiklikleri Dokümante Edin:
- Her migration dosyasının amacı, hangi tabloyu/sütunu etkilediği ve iş mantığına olan etkisi dokümante edilmelidir.
- Dokümantasyon, şema değişikliklerinin neden yapıldığını ve nasıl çalıştığını anlamayı kolaylaştırır.
- Örnek Dokümantasyon:
Migration: V2__add_email.sql Tarih: 2025-05-07 Amaç: Musteriler tablosuna e-posta alanı eklemek Etkilenen Tablo: Musteriler Değişiklik: Yeni sütun Email (VARCHAR(100)) eklendi
Test Ortamlarında Değişiklikleri Doğrulayın:
- Şema değişikliklerini önce bir geliştirme veya test ortamında uygulayın.
- Test ortamı, canlı sistemin bir kopyasını içermeli ve gerçek veriyle benzer senaryolar test edilmelidir.
- Örnek Test Senaryoları:
- Yeni sütun eklenmesi mevcut verileri etkiliyor mu?
- Yabancı anahtar eklenmesi veri bütünlüğünü bozuyor mu?
- Sorgu performansı nasıl etkileniyor?
Veri Bütünlüğünü Koruyun:
- Şema değişiklikleri, mevcut verilerin tutarlılığını bozmamalıdır. Örneğin:
- Yeni bir NOT NULL sütun ekleniyorsa, mevcut satırlara varsayılan bir değer atanmalıdır.
- Yabancı anahtar ekleniyorsa, mevcut verilerin bu kısıtlamaya uygun olduğundan emin olun.
- Örnek:
sql ALTER TABLE Musteriler ADD Durum VARCHAR(20) NOT NULL DEFAULT 'Aktif';
Performans Etkilerini Değerlendirin:
- Büyük ölçekli tablolarda şema değişiklikleri (örneğin, sütun ekleme, dizin oluşturma) uzun sürebilir ve tabloya erişimi kilitleyebilir.
- Performans etkisini en aza indirmek için:
- Değişiklikleri düşük trafik saatlerinde uygulayın.
- Büyük tablolarda çevrimiçi (online) şema değişikliklerini destekleyen DBMS özelliklerini kullanın (örneğin, PostgreSQL’de
CONCURRENTLYile dizin oluşturma).
- Örnek:
sql CREATE INDEX CONCURRENTLY idx_musteri_email ON Musteriler(Email);
Şema Değişikliklerini Otomatikleştirin:
- CI/CD (Continuous Integration/Continuous Deployment) pipeline’larına migration araçlarını entegre edin.
- Her yeni kod dağıtımıyla birlikte şema değişiklikleri otomatik olarak uygulanır.
- Örnek: GitHub Actions ile Flyway entegrasyonu:
yaml name: Deploy Database Migrations on: push jobs: migrate: runs-on: ubuntu-latest steps: - uses: actions/checkout@v3 - name: Run Flyway Migrations run: flyway migrate -url=jdbc:postgresql://db:5432/mydb -user=user -password=pass
Geri Dönüş Planı (Rollback Strategy):
- Her şema değişikliği için bir geri dönüş planı oluşturun. Bu, hata durumunda sistemi önceki duruma döndürmeyi kolaylaştırır.
- Geri dönüş için:
- Veritabanı yedekleri alın.
- Geri alma betiklerini hazır tutun.
- Kritik değişikliklerde, önce bir snapshot (örneğin, AWS RDS snapshot) alın.
Canlı Sistemlerde Şema Değişikliklerini Güvenli Bir Şekilde Uygulama
Canlı sistemlerde şema değişiklikleri, kullanıcı deneyimini veya veri bütünlüğünü etkilemeden uygulanmalıdır. Aşağıda, bu süreci güvenli bir şekilde yönetmek için adımlar ve teknikler sunulmaktadır:
1. Planlama ve Hazırlık
- Değişiklik Analizi:
- Değişikliğin kapsamını (tablolar, veriler, sorgular) ve potansiyel risklerini değerlendirin.
- Örneğin, bir sütun tipi değişikliği (
VARCHAR’danINT’e) veri kaybına neden olabilir mi? - Yedek Alma:
- Değişiklikten önce veritabanının tam bir yedeğini alın.
- Örnek: PostgreSQL’de:
bash pg_dump -U user -d mydb > backup_20250507.sql - Test Ortamında Deneme:
- Canlı sistemin bir kopyasında (staging) değişiklikleri test edin.
- Gerçek veriyle benzer senaryoları simüle edin (örneğin, yüksek trafik, büyük veri kümeleri).
- Düşük Trafik Zamanlaması:
- Değişiklikleri, sistemin en az kullanıldığı saatlerde uygulayın (örneğin, gece saatleri).
2. Güvenli Şema Değişiklik Türleri
Bazı şema değişiklikleri, canlı sistemlerde daha az risklidir ve doğrudan uygulanabilir. Diğerleri ise özel stratejiler gerektirir. İşte yaygın değişiklik türleri ve güvenli uygulama yöntemleri:
- Düşük Riskli Değişiklikler (Hemen Uygulanabilir):
- Yeni tablo veya sütun ekleme.
- Yeni dizin oluşturma (tercihen
CONCURRENTLY). - Varsayılan değer ekleme.
- Örnek:
ALTER TABLE Musteriler ADD YeniSutun VARCHAR(50); CREATE INDEX CONCURRENTLY idx_yeni_sutun ON Musteriler(YeniSutun); - Orta Riskli Değişiklikler (Dikkat Gerektirir):
- Sütun tipini değiştirme (örneğin,
VARCHAR(50)’danVARCHAR(100)’e). - Kısıtlamalar ekleme (örneğin, NOT NULL, FOREIGN KEY).
- Strateji: Mevcut verilerin yeni kısıtlamalara uygun olduğunu doğrulayın ve geçici tablolar veya veri dönüştürme betikleri kullanın.
- Örnek (NOT NULL ekleme):
-- Mevcut verilere varsayılan değer ata UPDATE Musteriler SET YeniSutun = 'Bilinmiyor' WHERE YeniSutun IS NULL; ALTER TABLE Musteriler ALTER COLUMN YeniSutun SET NOT NULL; - Yüksek Riskli Değişiklikler (Özel Stratejiler Gerektirir):
- Sütun silme, tablo yeniden yapılandırma, büyük tablolarda dizin kaldırma.
- Strateji: Sıfır kesinti (zero-downtime) teknikleri kullanın (aşağıda detaylı açıklanmıştır).
3. Sıfır Kesinti (Zero-Downtime) Şema Değişiklikleri
Büyük ölçekli veya 7/24 çalışan sistemlerde, şema değişiklikleri sistem kesintisi olmadan uygulanmalıdır. Yaygın sıfır kesinti stratejileri:
- Geçici Sütun/Tablo Kullanımı:
- Yeni bir sütun veya tablo oluşturun, verileri senkronize edin, ardından eski yapıyı kaldırın.
- Örnek:
MusterilertablosundaAdsütununuVARCHAR(50)’danTEXT’e dönüştürme:-- 1. Yeni bir sütun ekle ALTER TABLE Musteriler ADD AdYeni TEXT; -- 2. Verileri kopyala UPDATE Musteriler SET AdYeni = Ad; -- 3. Eski sütunu kaldır ve yeni sütunu yeniden adlandır ALTER TABLE Musteriler DROP COLUMN Ad; ALTER TABLE Musteriler RENAME COLUMN AdYeni TO Ad; - Tetikleyici ile Senkronizasyon:
- Yeni bir tablo veya sütun oluştururken, eski ve yeni yapılar arasında verileri senkronize etmek için tetikleyiciler kullanın.
- Örnek: Yeni bir tabloya geçiş:
-- Yeni tablo CREATE TABLE MusterilerYeni ( MusteriID INT PRIMARY KEY, Ad TEXT ); -- Tetikleyici: Eski tablodaki değişiklikleri yeniye yansıt CREATE TRIGGER sync_musteriler AFTER INSERT OR UPDATE ON Musteriler FOR EACH ROW EXECUTE FUNCTION sync_musteriler_to_new(); -- Verileri kopyala INSERT INTO MusterilerYeni SELECT MusteriID, Ad FROM Musteriler; -- Uygulamayı yeni tabloya yönlendir ve eskiyi kaldır - Gölge Tablo (Shadow Table):
- Yeni bir tablo oluşturun, verileri kopyalayın, uygulamayı yeni tabloya yönlendirin ve eski tabloyu kaldırın.
- Bu yöntem, büyük yeniden yapılandırmalarda kullanılır.
- Çevrimiçi Dizin Oluşturma:
- Dizin oluştururken tabloyu kilitlemekten kaçınmak için
CONCURRENTLYkullanın. - Örnek:
sql CREATE INDEX CONCURRENTLY idx_musteri_email ON Musteriler(Email);
4. Uygulama ve İzleme
- Değişiklikleri Uygulama:
- Migration aracını çalıştırarak değişiklikleri uygulayın (örneğin,
flyway migrate). - Küçük değişiklikleri gruplar halinde uygulayın, her gruptan sonra sistemi test edin.
- İzleme:
- Değişiklik sonrası veritabanı performansını (örneğin, sorgu süreleri, kilitlenme) izleyin.
- Hataları yakalamak için loglama ve izleme araçları kullanın (örneğin, PostgreSQL logları, New Relic).
- Hata Yönetimi:
- Hata durumunda, geri alma betiklerini çalıştırın veya yedeği geri yükleyin.
5. İletişim ve Koordinasyon
- Değişikliklerden etkilenecek ekipleri (örneğin, geliştiriciler, operasyon ekibi) önceden bilgilendirin.
- Değişiklik zamanlamasını ve etkilerini tüm paydaşlarla paylaşın.
- Örnek: Değişiklik öncesi bir duyuru:
Başlık: Veritabanı Şema Güncellemesi
Tarih: 2025-05-07 02:00
Etkilenen Sistem: Musteriler Tablosu
Değişiklik: Yeni Email sütunu eklenmesi
Tahmini Süre: 15 dakika
Geri Dönüş Planı: Yedek geri yükleme6. Post-Deployment Doğrulama
- Değişiklik sonrası, uygulamanın doğru çalıştığını ve veri bütünlüğünün korunduğunu doğrulayın.
- Örnek kontroller:
- Yeni sütunun beklendiği gibi çalıştığını test edin.
- İlişkili sorguların performansını kontrol edin.
- Veri tutarlılığını doğrulamak için örnek sorgular çalıştırın:
sql SELECT COUNT(*) FROM Musteriler WHERE Email IS NULL;
Gerçek Dünya Örneği
Bir e-ticaret platformunda yeni bir müşteri iletişim özelliği eklemek için şema değişikliği gerektiğini varsayalım. Musteriler tablosuna Telefon ve IletisimTercihi sütunları eklenmeli.
Adımlar:
Migration Dosyası Oluşturma:
-- V20250507_01_add_contact_info.sql
ALTER TABLE Musteriler ADD Telefon VARCHAR(15);
ALTER TABLE Musteriler ADD IletisimTercihi VARCHAR(20) DEFAULT 'Eposta';Test Ortamında Uygulama:
- Test veritabanında migration’ı çalıştırın:
bash flyway migrate -url=jdbc:postgresql://test-db:5432/mydb - Uygulamanın yeni sütunlarla çalıştığını doğrulayın.
Canlı Sistemde Uygulama:
- Düşük trafik saatinde (örneğin, 02:00) yedek alın:
bash pg_dump -U user -d mydb > backup_20250507.sql - Migration’ı uygulayın:
bash flyway migrate -url=jdbc:postgresql://prod-db:5432/mydb
Doğrulama:
- Yeni sütunların eklendiğini kontrol edin:
sql SELECT Telefon, IletisimTercihi FROM Musteriler LIMIT 10; - Uygulamanın doğru çalıştığını test edin.
Geri Dönüş Planı:
- Hata durumunda, sütunları kaldırın:
sql ALTER TABLE Musteriler DROP COLUMN Telefon; ALTER TABLE Musteriler DROP COLUMN IletisimTercihi; - Veya yedeği geri yükleyin:
bash psql -U user -d mydb < backup_20250507.sql
Modelleme Yöntemleri
ER (Entity-Relationship) Modelleme
ER Modellemede Temel Kavramlar
1. Varlıklar (Entities)
- Tanım: Gerçek dünyada benzersiz bir kimliğe sahip olan ve veritabanında saklanması gereken nesnelerdir. Varlıklar, bir tabloya karşılık gelir ve her varlık örneği bir satır olarak temsil edilir.
- Türleri:
- Güçlü Varlık (Strong Entity): Benzersiz bir birincil anahtara sahip olan varlıklar (örneğin,
Müşteri,Ürün). - Zayıf Varlık (Weak Entity): Kendi başına benzersiz bir kimliği olmayan ve başka bir güçlü varlığa bağlı olan varlıklar (örneğin, bir siparişin detayları).
- Özellikler (Attributes):
- Varlıkların özelliklerini tanımlar (örneğin,
MüşteriiçinAd,Soyad,Email). - Türleri: Basit (atomik), bileşik (örneğin,
AdresiçindeŞehir,PostaKodu), çok değerli (örneğin,TelefonNumaraları), türetilmiş (örneğin,Yaşdoğum tarihinden hesaplanır). - Temsil: ER diyagramında dikdörtgen ile gösterilir.
2. İlişkiler (Relationships)
- Tanım: Varlıklar arasındaki bağlantıları ifade eder. İlişkiler, veritabanında yabancı anahtarlar (foreign keys) ile uygulanır.
- Türleri:
- Bir-tek (1:1): Bir varlığın bir örneği, diğer varlığın yalnızca bir örneğiyle ilişkilidir (örneğin, bir
KullanıcıbirProfilile). - Bir-çok (1:N): Bir varlığın bir örneği, diğer varlığın birden fazla örneğiyle ilişkilidir (örneğin, bir
Müşteribirden fazlaSiparişverebilir). - Çok-çok (N:M): Her iki varlığın birden fazla örneği birbirine bağlanabilir (örneğin,
SiparişveÜrünarasında). Bu, bir ara tablo (junction table) ile uygulanır. - Temsil: ER diyagramında eşkenar dörtgen (diamond) veya doğrudan çizgilerle gösterilir.
3. Kardinalite Kısıtlamaları (Cardinality Constraints)
- Tanım: İlişkilerde, bir varlığın diğer varlıkla kaç örneğe bağlanabileceğini belirtir. Kardinalite, ilişkilerin doğasını ve veri bütünlüğünü tanımlar.
- Türleri:
- 1:1 (Bir-tek): Her varlık örneği, diğer varlığın yalnızca bir örneğiyle ilişkilidir.
- 1:N (Bir-çok): Bir varlık örneği, diğer varlığın birden fazla örneğiyle ilişkilidir.
- N:M (Çok-çok): Her iki varlığın birden fazla örneği ilişkilidir.
- Zorunlu (Mandatory): İlişki, bir varlık için zorunluysa, her örneğin ilişkide yer alması gerekir (örneğin, her
SiparişbirMüşteriye bağlı olmalı). - İsteğe Bağlı (Optional): İlişki zorunlu değilse, varlık örneği ilişkisiz olabilir (örneğin, bir
Müşterisipariş vermemiş olabilir). - Temsil:
- Çizgilerle bağlanan varlıklar arasında kardinalite sembolleri kullanılır:
1veya|: Tek bir örnek.NveyaM: Birden fazla örnek.0veyaO: İsteğe bağlı (sıfır veya daha fazla).
4. Zayıf Varlıklar ve Tanımlayıcı İlişkiler
- Zayıf varlıklar, güçlü varlıklara bağlıdır ve kendi birincil anahtarları yoktur. Tanımlayıcı ilişki (identifying relationship), zayıf varlığın kimliğini belirler.
- Temsil: Zayıf varlıklar çift çerçeveli dikdörtgenle, tanımlayıcı ilişkiler çift çizgili eşkenar dörtgenle gösterilir.
E-Ticaret Sistemi için ER Diyagramı Örneği
Bir e-ticaret sistemi için temel varlıkları ve ilişkileri ele alalım. Bu sistemde şu varlıkları ve ilişkileri modelleyeceğiz:
- Varlıklar:
Müşteri,Sipariş,Ürün,Kategori,SiparişDetayı(zayıf varlık). - İlişkiler: Müşterilerin sipariş vermesi, siparişlerin ürünleri içermesi, ürünlerin kategorilere ait olması.
- Kardinalite:
- Bir
Müşteribirden fazlaSiparişverebilir (1:N). - Bir
Sipariş, birden fazlaÜrüniçerebilir ve birÜrünbirden fazlaSiparişte yer alabilir (N:M). - Bir
Ürün, yalnızca birKategoriye aittir (N:1). SiparişDetayı,SiparişveÜrünarasında bir ara varlık olarak kullanılır.
ER Diyagramı Açıklaması
Aşağıda, e-ticaret sistemi için ER diyagramının metinsel bir temsili ve açıklaması yer alıyor. (Not: Grafiksel bir diyagram çizimi metin tabanlı bir ortamda sınırlıdır, bu nedenle metinsel bir temsil ve açıklamalar sunuyorum. Grafiksel diyagram için bir ER diyagram aracı, örneğin Lucidchart veya Draw.io, kullanılabilir.)
Varlıklar ve Özellikleri:
Müşteri (Güçlü Varlık)
- Özellikler:
MusteriID(PK),Ad,Soyad,Email,Telefon - Temsil:
[Müşteri]
Sipariş (Güçlü Varlık)
- Özellikler:
SiparisID(PK),MusteriID(FK),SiparisTarihi,ToplamTutar - Temsil:
[Sipariş]
Ürün (Güçlü Varlık)
- Özellikler:
UrunID(PK),UrunAdi,Fiyat,StokMiktari,KategoriID(FK) - Temsil:
[Ürün]
Kategori (Güçlü Varlık)
- Özellikler:
KategoriID(PK),KategoriAdi - Temsil:
[Kategori]
SiparişDetayı (Zayıf Varlık)
- Özellikler:
SiparisID(PK, FK),UrunID(PK, FK),Miktar,BirimFiyat - Temsil:
[[SiparişDetayı]]
İlişkiler ve Kardinalite:
Müşteri – Sipariş (1:N):
- Bir
Müşteri, sıfır veya daha fazlaSiparişverebilir (isteğe bağlı). - Her
Sipariş, tam olarak birMüşteriye bağlıdır (zorunlu). - Temsil:
[Müşteri] ----1:N----> [Sipariş]
Sipariş – SiparişDetayı (1:N, Tanımlayıcı İlişki):
- Bir
Sipariş, bir veya daha fazlaSiparişDetayıiçerir (zorunlu). - Her
SiparişDetayı, tam olarak birSiparişe bağlıdır (zayıf varlık bağı). - Temsil:
[Sipariş] ===1:N===> [[SiparişDetayı]](çift çizgi, tanımlayıcı ilişkiyi gösterir).
Ürün – SiparişDetayı (1:N, Tanımlayıcı İlişki):
- Bir
Ürün, sıfır veya daha fazlaSiparişDetayında yer alabilir (isteğe bağlı). - Her
SiparişDetayı, tam olarak birÜrüne bağlıdır. - Temsil:
[Ürün] ===1:N===> [[SiparişDetayı]]
Ürün – Kategori (N:1):
- Bir
Ürün, tam olarak birKategoriye aittir (zorunlu). - Bir
Kategori, sıfır veya daha fazlaÜrüniçerebilir (isteğe bağlı). - Temsil:
[Ürün] ----N:1----> [Kategori]
Metinsel ER Diyagramı Temsili:
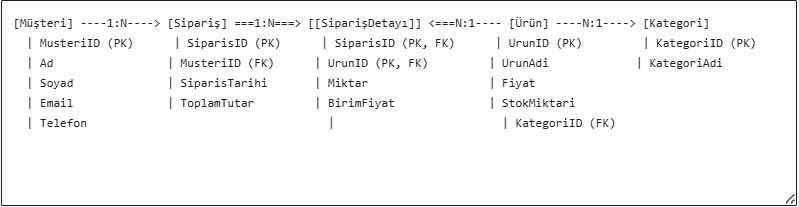
Açıklama:
MüşteriileSiparişarasında 1:N ilişkisi, bir müşterinin birden fazla sipariş verebileceğini gösterir.SipariştablosundaMusteriID, yabancı anahtar olarak bulunur.SiparişveÜrünarasında N:M ilişkisi olduğu içinSiparişDetayızayıf varlığı kullanılır. Bu, siparişin hangi ürünleri hangi miktarda içerdiğini temsil eder.SiparişDetayı, hemSiparişhem deÜrün’e bağlıdır ve her ikisinin birincil anahtarlarını içerir (SiparisID,UrunID).ÜrünileKategoriarasında N:1 ilişkisi, bir ürünün yalnızca bir kategoriye ait olduğunu, ancak bir kategorinin birden fazla ürün içerebileceğini gösterir.
SQL Şemasına Dönüşüm
ER diyagramını SQL şemasına dönüştürelim:
CREATE TABLE Kategoriler (
KategoriID INT PRIMARY KEY,
KategoriAdi VARCHAR(50) NOT NULL
);
CREATE TABLE Urunler (
UrunID INT PRIMARY KEY,
UrunAdi VARCHAR(100) NOT NULL,
Fiyat DECIMAL(10,2) NOT NULL,
StokMiktari INT CHECK (StokMiktari >= 0),
KategoriID INT NOT NULL,
FOREIGN KEY (KategoriID) REFERENCES Kategoriler(KategoriID)
);
CREATE TABLE Musteriler (
MusteriID INT PRIMARY KEY,
Ad VARCHAR(50) NOT NULL,
Soyad VARCHAR(50) NOT NULL,
Email VARCHAR(100) UNIQUE,
Telefon VARCHAR(15)
);
CREATE TABLE Siparisler (
SiparisID INT PRIMARY KEY,
MusteriID INT NOT NULL,
SiparisTarihi DATE NOT NULL,
ToplamTutar DECIMAL(10,2),
FOREIGN KEY (MusteriID) REFERENCES Musteriler(MusteriID)
);
CREATE TABLE SiparisDetaylari (
SiparisID INT,
UrunID INT,
Miktar INT NOT NULL CHECK (Miktar > 0),
BirimFiyat DECIMAL(10,2) NOT NULL,
PRIMARY KEY (SiparisID, UrunID),
FOREIGN KEY (SiparisID) REFERENCES Siparisler(SiparisID),
FOREIGN KEY (UrunID) REFERENCES Urunler(UrunID)
);Açıklama:
KategorilerveUrunlerarasında N:1 ilişkisi,Urunler.KategoriIDyabancı anahtarıyla uygulanır.MusterilerveSiparislerarasında 1:N ilişkisi,Siparisler.MusteriIDyabancı anahtarıyla temsil edilir.SiparisDetaylari, N:M ilişkisini çözmek için bir ara tablodur.SiparisIDveUrunIDbirleşik birincil anahtar olarak kullanılır.
Kardinalite Kısıtlamalarının Önemi
- Veri Bütünlüğü: Kardinalite, yabancı anahtarların doğru şekilde tanımlanmasını sağlar. Örneğin, bir
Sipariş’inMusteriID’si NULL olamaz (zorunlu ilişki). - Uygulama Mantığı: Kardinalite, iş kurallarını yansıtır. Örneğin, bir
Ürün’ün birKategori’ye zorunlu olarak bağlı olması, kategorisiz ürün olmamasını garanti eder. - Performans: Kardinalite, sorgu optimizasyonuna yardımcı olur. Örneğin, 1:N ilişkilerde birleştirme (join) işlemleri daha öngörülebilir olur.
Örnek Kardinalite Sorunları:
- Eğer
Sipariş–Müşteriilişkisi isteğe bağlı olsaydı (0:N), müşterisiz siparişler mümkün olurdu, bu da iş mantığına aykırı olabilir. - N:M ilişkisi için
SiparişDetayıkullanılmazsa, veri fazlalığı ve tutarsızlıklar ortaya çıkardı.
ER Diyagramının Grafiksel Temsili
Metin tabanlı bir ortamda grafiksel diyagram çizmek mümkün olmadığından, yukarıdaki metinsel temsil ve SQL kodu, diyagramın mantığını açıklar. Grafiksel bir diyagram oluşturmak için aşağıdaki adımları bir ER diyagram aracında (örneğin, Lucidchart, Draw.io) izleyebilirsiniz:
- Varlıkları Çizin:
Müşteri,Sipariş,Ürün,Kategoriiçin dikdörtgenler,SiparişDetayıiçin çift çerçeveli dikdörtgen. - Özellikleri Ekleyin: Her varlığın altına özelliklerini listeleyin (örneğin,
MusteriID,Ad). - İlişkileri Çizin: Varlıkları bağlayan çizgilerle ilişkileri gösterin (örneğin,
Müşteri–Siparişiçin 1:N). - Kardinaliteyi Belirtin: Çizgiler üzerinde 1, N, 0 gibi semboller kullanın.
- Tanımlayıcı İlişkileri Vurgulayın:
Sipariş–SiparişDetayıveÜrün–SiparişDetayıiçin çift çizgi kullanın.
Örnek Görselleştirme (Sözde Çizim):

UML (Unified Modeling Language) ile Veri Modelleme
UML Sınıf Diyagramlarının Veri Modellemede Kullanımı
UML sınıf diyagramları, veri modellemede şu şekilde kullanılır:
Varlıkların Tanımlanması:
- Her sınıf, veritabanındaki bir tabloya karşılık gelir. Sınıfın özellikleri (attributes), tablonun sütunlarını temsil eder.
- Örneğin, bir
Müşterisınıfı,Musterilertablosunu veMusteriID,Ad,Soyadgibi sütunları tanımlar.
İlişkilerin Modellenmesi:
- Sınıflar arasındaki ilişkiler (örneğin, birincil/yabancı anahtar ilişkileri), UML’de çeşitli ilişki türleriyle (birleşme, genelleştirme, agregasyon, kompozisyon) modellenir.
- Örneğin, bir
SiparişsınıfınınMüşterisınıfıyla 1:N ilişkisi, bir birleşme (association) ile gösterilir.
Kısıtlamaların Belirtilmesi:
- UML, veri kısıtlamalarını (örneğin, NOT NULL, UNIQUE) sınıf özelliklerinde veya ilişkilerde belirtebilir.
- Örneğin,
MusteriIDözelliği{unique, not null}olarak işaretlenir.
Nesne Yönelimli Tasarımın Entegrasyonu:
- UML sınıf diyagramları, veritabanı tasarımını uygulama katmanındaki nesne yönelimli kodla (örneğin, Java, Python sınıfları) hizalar. Bu, ORM (Object-Relational Mapping) araçlarıyla (örneğin, Hibernate, SQLAlchemy) uyumluluğu artırır.
Dokümantasyon ve İletişim:
- UML diyagramları, paydaşlar arasında teknik ve iş gereksinimlerini görselleştirir. Örneğin, bir e-ticaret sisteminin veri yapısını geliştiriciler ve iş analistleri için netleştirir.
Normalizasyon ve Optimizasyon:
- UML diyagramları, normalizasyon sürecini destekler. Örneğin, gereksiz veri fazlalığını tespit etmek için genelleştirme/özelleştirme kullanılabilir.
UML İlişki Türleri ve Örnekler
E-ticaret sistemi örneği üzerinden genelleştirme, özelleştirme, agregasyon ve kompozisyon ilişkilerini açıklayalım. Örnek senaryo: Bir e-ticaret platformunda Müşteri, Sipariş, Ürün, KrediKarti ve Adres gibi varlıkları modelleyeceğiz.
1. Genelleştirme (Generalization)
Tanım: Bir üst sınıf (genel sınıf) ile alt sınıflar (özel sınıflar) arasındaki “is-a” (bir türdür) ilişkisidir. Üst sınıf, ortak özellikleri ve davranışları tanımlar; alt sınıflar, üst sınıfı miras alır ve kendine özgü özellikler ekler.
Veri Modellemedeki Kullanımı:
Genelleştirme, ortak özellikleri paylaşan birden fazla varlığı tek bir üst sınıfta birleştirir ve veri fazlalığını azaltır.
Veritabanında, genelleştirme genellikle üç şekilde uygulanır:
Tek Tablo (Single Table): Tüm alt sınıflar tek bir tabloda saklanır, bir ayırt edici sütun (discriminator) kullanılır.
Sınıf Başına Tablo (Table per Class): Her alt sınıf için ayrı bir tablo oluşturulur.
Birleşik Tablo (Joined Table): Üst sınıf için bir tablo, her alt sınıf için ayrı tablolar oluşturulur.
Örnek:
E-ticaret sisteminde, Kullanıcı üst sınıfı, BireyselMusteri ve KurumsalMusteri alt sınıflarını genelleştirir.
UML Temsili:
[Kullanıcı]
| KullaniciID: INT {PK}
| Ad: STRING
| Soyad: STRING
| Email: STRING {unique}
^
|\
| \
| [BireyselMusteri] [KurumsalMusteri]
| | TCKimlikNo: STRING | SirketAdi: STRING
| | DogumTarihi: DATE | VergiNo: STRING- Açıklama:
Kullanıcısınıfı ortak özellikleri (Ad,Soyad,Email) içerir.BireyselMusteriveKurumsalMusteri,Kullanıcı’dan miras alır ve kendine özgü özellikleri ekler.
SQL Uygulaması (Tek Tablo Stratejisi):
CREATE TABLE Kullanicilar (
KullaniciID INT PRIMARY KEY,
Ad VARCHAR(50) NOT NULL,
Soyad VARCHAR(50) NOT NULL,
Email VARCHAR(100) UNIQUE,
Tip VARCHAR(20) NOT NULL, -- Ayırt edici: 'Bireysel' veya 'Kurumsal'
TCKimlikNo VARCHAR(11), -- Bireysel için
DogumTarihi DATE, -- Bireysel için
SirketAdi VARCHAR(100), -- Kurumsal için
VergiNo VARCHAR(20) -- Kurumsal için
);Avantajları:
Veri fazlalığını azaltır.
Ortak özelliklerin yönetimini kolaylaştırır.
Dezavantajları:
Tek tablo stratejisi, NULL değerlerin artmasına neden olabilir.
Sorgular karmaşıklaşabilir.
2. Özelleştirme (Specialization)
Tanım: Genelleştirmenin tersidir; bir üst sınıfın özelliklerini miras alan alt sınıfların özelleştirilmiş özellikler eklemesidir. Genelleştirme ve özelleştirme aynı ilişkinin iki yönünü ifade eder.
Veri Modellemedeki Kullanımı:
Özelleştirme, farklı varlık türlerinin özel ihtiyaçlarını karşılamak için kullanılır.
Veritabanında, genelleştirme ile aynı uygulama stratejileri (tek tablo, sınıf başına tablo, birleşik tablo) kullanılır.
Örnek:
Yukarıdaki genelleştirme örneğinde, BireyselMusteri ve KurumsalMusteri, Kullanıcı sınıfının özelleştirilmiş alt sınıflarıdır.
SQL Uygulaması (Birleşik Tablo Stratejisi):
CREATE TABLE Kullanicilar (
KullaniciID INT PRIMARY KEY,
Ad VARCHAR(50) NOT NULL,
Soyad VARCHAR(50) NOT NULL,
Email VARCHAR(100) UNIQUE
);
CREATE TABLE BireyselMusteriler (
KullaniciID INT PRIMARY KEY,
TCKimlikNo VARCHAR(11),
DogumTarihi DATE,
FOREIGN KEY (KullaniciID) REFERENCES Kullanicilar(KullaniciID)
);
CREATE TABLE KurumsalMusteriler (
KullaniciID INT PRIMARY KEY,
SirketAdi VARCHAR(100),
VergiNo VARCHAR(20),
FOREIGN KEY (KullaniciID) REFERENCES Kullanicilar(KullaniciID)
);Avantajları:
Daha az NULL değer, daha temiz veri modeli.
Her alt sınıf için özel sorgular yazılabilir.
Dezavantajları:
Birleştirme (join) işlemleri gerekebilir, bu da performansı etkileyebilir.
3. Agregasyon (Aggregation)
Tanım: Bir “has-a” (sahiptir) ilişkisidir ve bir sınıfın başka bir sınıfın örneklerini içerdiğini gösterir. Agregasyon, sınıflar arasında gevşek bir bağımlılığı ifade eder; birleştirilen nesneler bağımsız olarak var olabilir.
Veri Modellemedeki Kullanımı:
Agregasyon, bir varlığın başka bir varlıkla isteğe bağlı veya geçici bir ilişki içinde olduğunu gösterir.
Veritabanında genellikle 1:N veya N:M ilişkilerle uygulanır ve yabancı anahtarlarla temsil edilir.
Örnek:
Bir Sipariş, birden fazla Ürün içerebilir, ancak Ürün’ler Sipariş’ten bağımsız olarak var olabilir (sipariş silindiğinde ürünler silinmez).
UML Temsili:
[Sipariş] ◇----1:N----> [Ürün]
| SiparisID: INT {PK} | UrunID: INT {PK}
| SiparisTarihi: DATE | UrunAdi: STRING
| ToplamTutar: DECIMAL | Fiyat: DECIMAL- Açıklama:
◇sembolü agregasyonu gösterir.SiparişveÜrünarasında N:M ilişkisi vardır, bu nedenle bir ara tablo (SiparişDetayı) kullanılır.
SQL Uygulaması:
CREATE TABLE Siparisler (
SiparisID INT PRIMARY KEY,
SiparisTarihi DATE NOT NULL,
ToplamTutar DECIMAL(10,2)
);
CREATE TABLE Urunler (
UrunID INT PRIMARY KEY,
UrunAdi VARCHAR(100) NOT NULL,
Fiyat DECIMAL(10,2) NOT NULL
);
CREATE TABLE SiparisDetaylari (
SiparisID INT,
UrunID INT,
Miktar INT NOT NULL,
BirimFiyat DECIMAL(10,2),
PRIMARY KEY (SiparisID, UrunID),
FOREIGN KEY (SiparisID) REFERENCES Siparisler(SiparisID),
FOREIGN KEY (UrunID) REFERENCES Urunler(UrunID)
);Avantajları:
Esnek bir ilişki modeli sağlar.
Varlıkların bağımsızlığı, veri yönetimini kolaylaştırır.
Dezavantajları:
Ara tablolar, sorgu karmaşıklığını artırabilir.
4. Kompozisyon (Composition)
Tanım: Daha güçlü bir “has-a” ilişkisidir ve bir sınıfın başka bir sınıfın parçalarını içerdiğini gösterir. Kompozisyonda, bütün (whole) olmadan parçalar (parts) var olamaz; yani, bütün silindiğinde parçalar da silinir.
Veri Modellemedeki Kullanımı:
Kompozisyon, bir varlığın yaşam döngüsünün başka bir varlığa sıkı sıkıya bağlı olduğu durumlarda kullanılır.
Veritabanında genellikle 1:N ilişkilerle uygulanır ve ON DELETE CASCADE gibi kısıtlamalarla desteklenir.
Örnek:
Bir Müşteri, birden fazla Adres’e sahip olabilir, ancak bu adresler yalnızca o müşteriye aittir. Müşteri silindiğinde, adresler de silinmelidir.
UML Temsili:
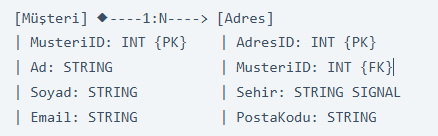
- Açıklama:
◆sembolü kompozisyonu gösterir.Adres,Müşteriolmadan var olamaz.
SQL Uygulaması: CREATE TABLE Musteriler ( MusteriID INT PRIMARY KEY, Ad VARCHAR(50) NOT NULL, Soyad VARCHAR(50) NOT NULL, Email VARCHAR(100) UNIQUE ); CREATE TABLE Adresler ( AdresID INT PRIMARY KEY, MusteriID INT NOT NULL, Sehir VARCHAR(50), PostaKodu VARCHAR(10), FOREIGN KEY (MusteriID) REFERENCES Musteriler(MusteriID) ON DELETE CASCADE );
Avantajları:
Veri bütünlüğünü korur (örneğin, yetim adreslerin oluşmasını engeller).
Yaşam döngüsü bağımlılığı açıkça tanımlanır.
Dezavantajları:
Sıkı bağımlılık, esnekliği azaltabilir.
E-Ticaret Sistemi için UML Sınıf Diyagramı Örneği
Aşağıda, e-ticaret sistemi için bir UML sınıf diyagramının metinsel temsili ve açıklaması yer alıyor. (Grafiksel bir diyagram için Lucidchart, Draw.io gibi araçlar kullanılabilir.)
Sınıflar ve İlişkiler:
[Kullanıcı]
| KullaniciID: INT {PK}
| Ad: STRING
| Soyad: STRING
| Email: STRING {unique}
^
|\
| \
| [BireyselMusteri] ◇----1:N----> [Sipariş] ◇----N:M----> [Ürün]
| | TCKimlikNo: STRING | SiparisID: INT {PK} | UrunID: INT {PK}
| | DogumTarihi: DATE | SiparisTarihi: DATE | UrunAdi: STRING
| | ToplamTutar: DECIMAL | Fiyat: DECIMAL
| [KurumsalMusteri] ◆----1:N----> [Adres]
| | SirketAdi: STRING | AdresID: INT {PK}
| | VergiNo: STRING | MusteriID: INT {FK}
| | Sehir: STRING
| | PostaKodu: STRINGAçıklama:
Genelleştirme/Özelleştirme:
Kullanıcıüst sınıfı,BireyselMusteriveKurumsalMusterialt sınıflarını genelleştirir. Ortak özellikler (Ad,Soyad,Email)Kullanıcı’da tanımlanır.
Agregasyon:
SiparişileÜrünarasında N:M agregasyon ilişkisi vardır. Bu,SiparişDetayıara tablosuyla uygulanır (diyagramda gösterilmemiştir, ancak SQL’de tanımlanır).BireyselMusteriileSiparişarasında 1:N agregasyon ilişkisi vardır; siparişler müşteriden bağımsız olarak var olabilir.
Kompozisyon:
KurumsalMusteriileAdresarasında 1:N kompozisyon ilişkisi vardır. Adresler, yalnızca ilgili müşteriye aittir ve müşteri silindiğinde adresler de silinir.
Kısıtlamalar:
KullaniciID,SiparisID,UrunID,AdresIDbirincil anahtar olarak işaretlenir ({PK}).Emailbenzersizdir ({unique}).
SQL Şeması:
CREATE TABLE Kullanicilar (
KullaniciID INT PRIMARY KEY,
Ad VARCHAR(50) NOT NULL,
Soyad VARCHAR(50) NOT NULL,
Email VARCHAR(100) UNIQUE,
Tip VARCHAR(20) NOT NULL -- 'Bireysel' veya 'Kurumsal'
);
CREATE TABLE BireyselMusteriler (
KullaniciID INT PRIMARY KEY,
TCKimlikNo VARCHAR(11),
DogumTarihi DATE,
FOREIGN KEY (KullaniciID) REFERENCES Kullanicilar(KullaniciID)
);
CREATE TABLE KurumsalMusteriler (
KullaniciID INT PRIMARY KEY,
SirketAdi VARCHAR(100),
VergiNo VARCHAR(20),
FOREIGN KEY (KullaniciID) REFERENCES Kullanicilar(KullaniciID)
);
CREATE TABLE Adresler (
AdresID INT PRIMARY KEY,
MusteriID INT NOT NULL,
Sehir VARCHAR(50),
PostaKodu VARCHAR(10),
FOREIGN KEY (MusteriID) REFERENCES KurumsalMusteriler(KullaniciID) ON DELETE CASCADE
);
CREATE TABLE Siparisler (
SiparisID INT PRIMARY KEY,
MusteriID INT NOT NULL,
SiparisTarihi DATE NOT NULL,
ToplamTutar DECIMAL(10,2),
FOREIGN KEY (MusteriID) REFERENCES BireyselMusteriler(KullaniciID)
);
CREATE TABLE Urunler (
UrunID INT PRIMARY KEY,
UrunAdi VARCHAR(100) NOT NULL,
Fiyat DECIMAL(10,2) NOT NULL
);
CREATE TABLE SiparisDetaylari (
SiparisID INT,
UrunID INT,
Miktar INT NOT NULL,
BirimFiyat DECIMAL(10,2),
PRIMARY KEY (SiparisID, UrunID),
FOREIGN KEY (SiparisID) REFERENCES Siparisler(SiparisID),
FOREIGN KEY (UrunID) REFERENCES Urunler(UrunID)
);UML Sınıf Diyagramlarının Veri Modellemedeki Avantajları
- Soyutlama: İş mantığını teknik detaylardan ayırır.
- Esneklik: Nesne yönelimli tasarım ile veritabanı tasarımı arasında köprü kurar.
- İletişim: Paydaşlar arasında net bir görsel iletişim sağlar.
- Normalizasyon Desteği: Genelleştirme ve özelleştirme, veri fazlalığını azaltır.
- Hata Önleme: İlişkilerin (agregasyon, kompozisyon) açıkça tanımlanması, tasarım hatalarını azaltır.
Domain Driven Design ve Veri Modelleme
DDD Prensiplerinin Veri Modellemede Uygulanması
DDD, veri modellemede iş mantığını ve iş alanını (domain) ön planda tutar. Temel prensipler ve bunların veri modellemedeki uygulamaları şunlardır:
Ubiquitous Language (Ortak Dil):
- İş uzmanları, geliştiriciler ve diğer paydaşlar arasında ortak bir dil kullanılır. Bu dil, hem kodda hem de veritabanı tasarımında tutarlı bir şekilde yansıtılır.
- Veri Modellemedeki Uygulama: Tablo ve sütun isimleri, iş terimlerini yansıtır (örneğin,
OrderyerineSipariş,CustomeryerineMüşteri).
Bounded Context:
- İş alanını daha küçük, bağımsız bağlamlara böler. Her bağlam, kendi modelini ve dilini tanımlar, böylece karmaşıklık azalır.
- Veri Modellemedeki Uygulama: Her bağlam için ayrı bir şema veya veritabanı kullanılır, böylece farklı bağlamlar arasında çakışmalar önlenir.
Varlık (Entity):
- Benzersiz bir kimliğe sahip olan ve yaşam döngüsü boyunca izlenen nesnelerdir.
- Veri Modellemedeki Uygulama: Varlıklar, veritabanında birincil anahtar (primary key) ile tanımlı tablolar olarak modellenir.
Değer Nesnesi (Value Object):
- Kimlikten ziyade özellikleriyle tanımlanan, değişmez (immutable) nesnelerdir.
- Veri Modellemedeki Uygulama: Değer nesneleri, ayrı tablolar yerine genellikle bir varlığın sütunları veya gömülü yapılar olarak saklanır.
Toplu Kök (Aggregate Root):
- Bir grup varlığı ve değer nesnesini bir arada yöneten, veri bütünlüğünü sağlayan bir varlıktır. Dış dünya, yalnızca toplu kök üzerinden bu gruba erişir.
- Veri Modellemedeki Uygulama: Toplu kök, bir tablo olarak modellenir ve ilgili varlık/değer nesneleriyle ilişkiler (yabancı anahtarlar) aracılığıyla bağlanır.
Repository:
- Veritabanı ile uygulama arasındaki veri erişimini soyutlar. Toplu kökleri saklamak ve almak için kullanılır.
- Veri Modellemedeki Uygulama: Repository, SQL sorgularını veya ORM (Object-Relational Mapping) işlemlerini kapsar.
Domain Events:
- İş mantığında önemli olayları temsil eder (örneğin, bir siparişin tamamlanması).
- Veri Modellemedeki Uygulama: Olaylar, bir olay günlüğü tablosunda saklanabilir veya mesaj kuyruklarına (örneğin, Kafka) gönderilebilir.
E-Ticaret Sistemi Örneği Üzerinden DDD Kavramları
Bir e-ticaret platformunda, sipariş yönetimi ve müşteri yönetimi işlevlerini modelleyelim. Bu örnekte, DDD prensiplerini veri modellemede nasıl uygulayacağımızı göstereceğim.
1. Bounded Context
Tanım: İş alanını bağımsız bağlamlara böler. Her bağlam, kendi modelini ve dilini tanımlar, böylece farklı bağlamlar arasında anlam karışıklığı önlenir.
E-Ticaret Örneği:
- Sipariş Yönetimi Bağlamı: Sipariş oluşturma, ürün ekleme, ödeme işlemleri gibi işlevleri kapsar.
- Müşteri Yönetimi Bağlamı: Müşteri profilleri, adresler ve iletişim bilgileri gibi işlevleri kapsar.
- Her bağlam için ayrı bir veritabanı şeması veya modül oluşturulabilir, ancak bağlamlar arasında entegrasyon gerekebilir (örneğin, bir siparişin müşteri bilgilerine ihtiyacı vardır).
Veri Modellemedeki Uygulama:
- Sipariş Yönetimi Şeması (
orders):Sipariş,SiparişKalemi,Ödemegibi tablolar içerir. - Müşteri Yönetimi Şeması (
crm):Müşteri,Adresgibi tablolar içerir. - SQL Örneği:
CREATE SCHEMA orders;
CREATE SCHEMA crm;Neden Önemli?:
- Sipariş Yönetiminde
Müşteri, yalnızcaMusteriIDve temel bilgilerle ilgilenirken, Müşteri Yönetiminde detaylı profil bilgileri (örneğin,DogumTarihi) yer alır. Bu ayrım, her bağlamın kendi modelini optimize etmesini sağlar.
2. Varlık (Entity)
Tanım: Benzersiz bir kimliğe sahip, yaşam döngüsü boyunca izlenen nesnelerdir. Varlıkların kimlikleri, onları diğer nesnelerden ayırır.
E-Ticaret Örneği:
- Müşteri: Her müşteri, benzersiz bir
MusteriIDile tanımlanır. Müşterinin adı veya adresi değişebilir, ancak kimliği sabittir. - Sipariş: Her sipariş, benzersiz bir
SiparisIDile tanımlanır. Siparişin durumu (örneğin, “Onaylandı”, “Kargoda”) değişebilir.
Veri Modellemedeki Uygulama:
- Varlıklar, birincil anahtarlarla tanımlı tablolar olarak modellenir.
- SQL Örneği:
CREATE TABLE crm.Musteriler (
MusteriID INT PRIMARY KEY,
Ad VARCHAR(50) NOT NULL,
Soyad VARCHAR(50) NOT NULL,
Email VARCHAR(100) UNIQUE
);
CREATE TABLE orders.Siparisler (
SiparisID INT PRIMARY KEY,
MusteriID INT NOT NULL,
SiparisTarihi DATE NOT NULL,
Durum VARCHAR(20) NOT NULL,
FOREIGN KEY (MusteriID) REFERENCES crm.Musteriler(MusteriID)
);Neden Önemli?:
MusteriIDveSiparisID, varlıkların benzersizliğini sağlar ve yaşam döngüsü boyunca (örneğin, sipariş durumu değiştiğinde) izlenebilirliği korur.
3. Değer Nesnesi (Value Object)
Tanım: Kimlikten ziyade özellikleriyle tanımlanan, değişmez nesnelerdir. Değer nesneleri, genellikle bir varlığın parçasıdır ve kendi başlarına bir yaşam döngüsüne sahip değildir.
E-Ticaret Örneği:
- Adres: Bir müşterinin adresi (örneğin,
Sehir,PostaKodu), benzersiz bir kimliğe sahip değildir; yalnızca özellikleriyle tanımlanır. - Para: Bir siparişin toplam tutarı (örneğin,
100.50 USD), miktar ve para birimiyle tanımlanır.
Veri Modellemedeki Uygulama:
- Değer nesneleri, genellikle bir varlığın tablosunda sütunlar olarak veya gömülü yapılar olarak saklanır. Büyük veya tekrarlanan değer nesneleri için ayrı tablolar kullanılabilir.
- SQL Örneği (Adres için):
CREATE TABLE crm.Adresler (
AdresID INT PRIMARY KEY,
MusteriID INT NOT NULL,
Sehir VARCHAR(50),
PostaKodu VARCHAR(10),
Ulke VARCHAR(50),
FOREIGN KEY (MusteriID) REFERENCES crm.Musteriler(MusteriID) ON DELETE CASCADE
);- Alternatif olarak, adres bilgileri
Musterilertablosuna gömülebilir:
ALTER TABLE crm.Musteriler
ADD Sehir VARCHAR(50),
ADD PostaKodu VARCHAR(10),
ADD Ulke VARCHAR(50);- SQL Örneği (Para için):
ALTER TABLE orders.Siparisler
ADD ToplamTutar DECIMAL(10,2),
ADD ParaBirimi VARCHAR(3) DEFAULT 'USD';Neden Önemli?:
- Değer nesneleri, iş mantığını sadeleştirir ve veri tutarlılığını sağlar. Örneğin,
Adresdeğişmez bir yapı olarak modellenirse, her değişiklik yeni bir adres nesnesi oluşturur, bu da geçmiş verilerin korunmasını sağlar.
4. Toplu Kök (Aggregate Root)
Tanım: Bir toplu (aggregate), bir grup varlığı ve değer nesnesini bir arada tutan ve veri bütünlüğünü sağlayan bir varlıktır. Dış dünya, yalnızca toplu kök üzerinden bu gruba erişir.
E-Ticaret Örneği:
- Sipariş Toplusu:
- Toplu Kök:
Sipariş - İçerdiği Nesneler:
- Varlık:
SiparişKalemi(bir siparişin içerdiği ürünler) - Değer Nesnesi:
Para(sipariş toplamı),Adres(teslimat adresi)
- Varlık:
- İş Kuralı: Bir siparişin durumu, yalnızca
Siparişüzerinden değiştirilebilir (örneğin, “Kargoda” durumuna geçerken tüm kalemler kontrol edilir).
Veri Modellemedeki Uygulama:
- Toplu kök, bir tablo olarak modellenir ve ilgili nesneler, yabancı anahtarlarla bağlanır. Toplu kök, veri erişiminde sınırları belirler.
- SQL Örneği:
CREATE TABLE orders.Siparisler (
SiparisID INT PRIMARY KEY,
MusteriID INT NOT NULL,
SiparisTarihi DATE NOT NULL,
Durum VARCHAR(20) NOT NULL,
ToplamTutar DECIMAL(10,2),
ParaBirimi VARCHAR(3) DEFAULT 'USD',
TeslimatSehir VARCHAR(50), -- Değer nesnesi: Teslimat Adresi
TeslimatPostaKodu VARCHAR(10),
TeslimatUlke VARCHAR(50),
FOREIGN KEY (MusteriID) REFERENCES crm.Musteriler(MusteriID)
);
CREATE TABLE orders.SiparisKalemleri (
SiparisKalemiID INT PRIMARY KEY,
SiparisID INT NOT NULL,
UrunID INT NOT NULL,
Miktar INT NOT NULL CHECK (Miktar > 0),
BirimFiyat DECIMAL(10,2) NOT NULL,
FOREIGN KEY (SiparisID) REFERENCES orders.Siparisler(SiparisID) ON DELETE CASCADE,
FOREIGN KEY (UrunID) REFERENCES orders.Urunler(UrunID)
);
CREATE TABLE orders.Urunler (
UrunID INT PRIMARY KEY,
UrunAdi VARCHAR(100) NOT NULL,
Fiyat DECIMAL(10,2) NOT NULL
);- Açıklama:
Sipariş, toplu köktür veSiparisIDile tanımlanır.SiparişKalemleri,Sipariş’e bağlı bir varlıktır veON DELETE CASCADEile sipariş silindiğinde kalemler de silinir.TeslimatSehir,TeslimatPostaKodu,TeslimatUlkeveToplamTutar,ParaBirimideğer nesneleridir veSipariştablosuna gömülüdür.- Dış dünya (örneğin, uygulama),
SiparişKalemleri’ne doğrudan erişemez; yalnızcaSiparişüzerinden erişilir.
Neden Önemli?:
- Toplu kök, veri bütünlüğünü korur. Örneğin, bir siparişin toplam tutarı, kalemlerin birim fiyatları ve miktarlarıyla tutarlı olmalıdır. Bu kontrol,
Sipariştoplu kökü tarafından yapılır.
E-Ticaret Sistemi için UML Sınıf Diyagramı ile DDD Modeli
Aşağıda, e-ticaret sisteminin DDD tabanlı bir UML sınıf diyagramının metinsel temsili yer alıyor. (Grafiksel diyagram için Lucidchart veya Draw.io kullanılabilir.)
UML Temsili:
Bounded Context: Sipariş Yönetimi
[Sipariş] (Aggregate Root)
| SiparisID: INT {PK}
| MusteriID: INT {FK}
| SiparisTarihi: DATE
| Durum: STRING
| ToplamTutar: DECIMAL
| ParaBirimi: STRING
| TeslimatAdresi: Adres
| + degistirDurum(yeniDurum: STRING)
◆----1:N----> [SiparişKalemi]
| SiparisKalemiID: INT {PK}
| SiparisID: INT {FK}
| UrunID: INT {FK}
| Miktar: INT
| BirimFiyat: DECIMAL
◇----N:1----> [Ürün]
| UrunID: INT {PK}
| UrunAdi: STRING
| Fiyat: DECIMAL
Bounded Context: Müşteri Yönetimi
[Müşteri] (Aggregate Root)
| MusteriID: INT {PK}
| Ad: STRING
| Soyad: STRING
| Email: STRING {unique}
| + guncelleEmail(yeniEmail: STRING)
◆----1:N----> [Adres] (Value Object)
| Sehir: STRING
| PostaKodu: STRING
| Ulke: STRINGAçıklama:
- Bounded Context:
Sipariş Yönetimi:Sipariş,SiparişKalemi,Ürünve ilgili iş mantığını içerir.Müşteri Yönetimi:MüşteriveAdres’i içerir.- Varlık:
Sipariş,SiparişKalemi,ÜrünveMüşteri, benzersiz kimlikleriyle varlıklardır.- Değer Nesnesi:
Adres, kimlikten ziyade özellikleriyle (Sehir,PostaKodu,Ulke) tanımlanır.SiparişiçindekiTeslimatAdresiveToplamTutar/ParaBirimide değer nesneleridir.- Toplu Kök:
Sipariş,SiparişKalemleriveTeslimatAdresi’ni kapsayan bir toplu köktür. Uygulama, kalemlere doğrudan erişemez;Siparişüzerinden erişir.Müşteri,Adres’leri kapsayan bir toplu köktür.
DDD’nin Veri Modellemedeki Avantajları
İş Mantığı Odaklı Tasarım:
- Veritabanı, iş kurallarını (örneğin, sipariş durumu geçişleri) doğru bir şekilde yansıtır.
Esneklik ve Sürdürülebilirlik:
- Bounded Context’ler, farklı iş alanlarını izole ederek değişiklikleri kolaylaştırır.
Veri Bütünlüğü:
- Toplu kökler, ilgili nesneler arasında tutarlılığı sağlar.
Kod-Veritabanı Uyumu:
- Varlık ve değer nesneleri, uygulama kodundaki sınıflarla hizalanır (örneğin, ORM ile).
Karmaşıklığın Azaltılması:
- Bounded Context’ler, büyük sistemleri yönetilebilir parçalara böler.
Kaynakça:
- https://www.w3schools.com/sql/sql_constraints.asp
- https://www.postgresql.org/docs/current/ddl-schemas.html
- https://docs.liquibase.com/start/design-liquibase-project.html
- https://www.geeksforgeeks.org/introduction-of-er-model/
- https://learn.microsoft.com/en-us/sql/?view=sql-server-ver16
- https://www.postgresql.org/docs/
- https://docs.oracle.com/en/database/oracle/oracle-database/21/cncpt/introduction-to-oracle-database.html
- https://www.postgresql.org/docs/current/indexes.html
- https://www.lucidchart.com/pages/er-diagrams
- https://www.w3schools.com/sql/sql_null_values.asp
- https://www.studytonight.com/dbms/database-normalization.php
- https://www.dreamstime.com/data-modeling-vector-icon-filled-flat-sign-mobile-concept-web-design-glyph-symbol-logo-illustration-graphics-image290782108
Bir şeyi başarmak ne kadar zorsa, zaferin tadı o kadar güzeldir.
Pele
Bir sonraki yazıda görüşmek dileğiyle!”



